
Neste artigo, vamos explorar o fascinante mundo da inteligência artificial e como ela pode ser aplicada no desenvolvimento frontend design AI. Vamos desenvolver juntos um agente RAG (Retrieval-Augmented Generation) utilizando Langflow e Pinecone, ideal para oferecer suporte técnico de forma autônoma e eficiente.
Índice
- 🛠️ Introdução ao Desenvolvimento do Agente RAG
- 🤖 O Que é um Agente de IA?
- 📊 Casos de Uso dos Agentes de IA
- 📚 A Importância das Fontes de Conhecimento Externas
- 🔄 Entendendo o Fluxo de Conversa com Agentes de IA
- 📦 O Papel das Vector Databases
- 🚀 Como Funciona o Agente RAG?
- 📊 Explorando as Vectodeira Bases
- 🗂️ Estrutura das Vector Databases
- 🔄 Fluxo de Consulta do Agente de IA
- 🏗️ Construindo o Agente de IA
- 📥 Etapa de Ingestão de Dados
- ⚙️ Configurando o Ambiente Necessário
- 🔗 Construindo o Pipeline de Dados
- 📂 Dividindo Documentos em Tanques
- 🔗 Integrando com o Pinecone
- ⚙️ Finalizando a Configuração do Agente
- 🔄 Fluxo de Recuperação de Dados
- 🧪 Testando o Agente de IA
- 📌 Considerações Finais e Expansões Futuras
- ❓ FAQ
🛠️ Introdução ao Desenvolvimento do Agente RAG
O desenvolvimento de agentes de IA, especialmente os agentes RAG, representa uma evolução significativa na forma como interagimos com sistemas de suporte técnico. Esses agentes são projetados para serem autônomos, dinâmicos e inteligentes, utilizando fontes de conhecimento externas para oferecer respostas precisas e relevantes. A ideia principal é que, ao integrar inteligência artificial ao design frontend, podemos criar soluções que não apenas respondem perguntas, mas que também aprendem e se adaptam ao longo do tempo.
Por que RAG?
A sigla RAG, que significa Retrieval-Augmented Generation, descreve um método que combina modelos de linguagem com sistemas de busca. Isso permite que os agentes acessem informações atualizadas e especializadas que não estavam incluídas em seu treinamento original. Essa abordagem é especialmente útil em cenários onde informações críticas precisam ser recuperadas rapidamente.

🤖 O Que é um Agente de IA?
Um agente de IA é um sistema que interage com usuários e fontes de conhecimento de forma autônoma. Esses agentes são capazes de realizar tarefas específicas, como fornecer suporte técnico ou auxiliar em processos de compliance. A sua eficácia depende da capacidade de acessar e interpretar informações externas, que muitas vezes são confidenciais ou proprietárias.
Características dos Agentes de IA
- Autonomia: Capacidade de operar sem intervenção humana constante.
- Interação Dinâmica: Respostas adaptativas com base nas consultas dos usuários.
- Acesso a Fontes Externas: Utilização de bancos de dados e documentações atualizadas.

📊 Casos de Uso dos Agentes de IA
Os agentes de IA têm uma variedade de aplicações práticas. Vamos explorar alguns dos casos de uso mais relevantes:
1. Suporte Técnico
Agentes que ajudam usuários a resolver problemas técnicos, utilizando documentações e manuais atualizados.
2. Onboarding de Funcionários
Agentes que orientam novos colaboradores, oferecendo informações sobre políticas internas e procedimentos.
3. Compliance Jurídico
Agentes que garantem que as práticas empresariais estejam em conformidade com regulamentações legais.

📚 A Importância das Fontes de Conhecimento Externas
A eficácia de um agente de IA depende fortemente do acesso a fontes de conhecimento externas. Essas fontes podem incluir documentações técnicas, bases de dados e outros recursos especializados que não estão contidos no treinamento original do modelo.
Tipos de Fontes de Conhecimento
- Documentações Técnicas: Manuais e fichas técnicas que detalham produtos e serviços.
- Dados Proprietários: Informações exclusivas que são cruciais para a tomada de decisões.
- Informações Recentes: Dados atualizados que refletem as últimas mudanças no setor.
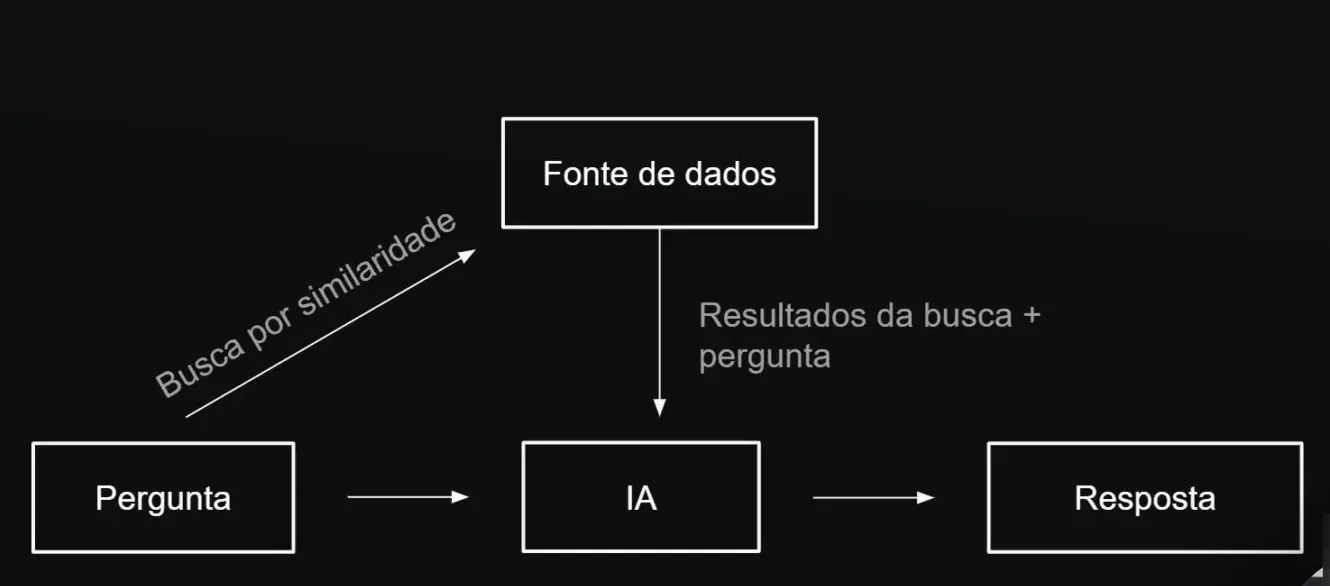
🔄 Entendendo o Fluxo de Conversa com Agentes de IA
O fluxo de conversa com um agente de IA é fundamental para a interação eficaz. Vamos detalhar como esse fluxo se diferencia de um modelo de linguagem simples.
Fluxo de Conversa Tradicional vs. Fluxo com RAG
- Modelo de Linguagem Simples: O usuário faz uma pergunta, a IA processa e responde com base no conhecimento treinado.
- Agente RAG: O usuário faz uma pergunta, a IA consulta uma fonte de dados externa, processa as informações e, então, responde.
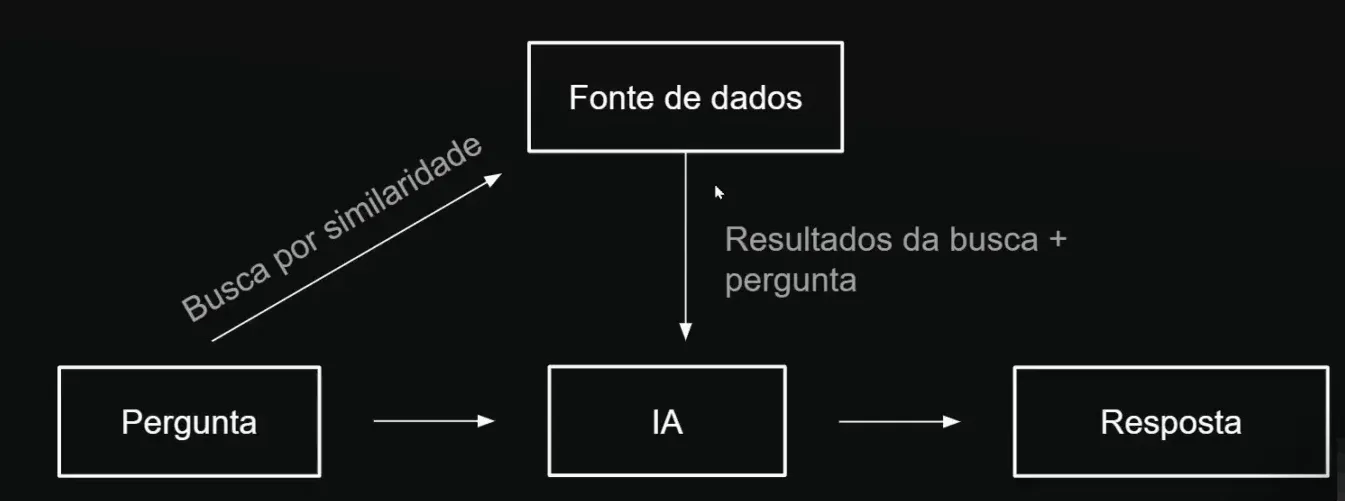
📦 O Papel das Vector Databases
As Vector Databases são componentes essenciais para o funcionamento dos agentes RAG. Elas permitem armazenar informações de forma que possam ser facilmente pesquisadas pela IA.
Como Funcionam as Vector Databases?
- Armazenamento Eficiente: Informações são armazenadas em um formato que permite consultas rápidas.
- Consultas por Similaridade: Capacidade de encontrar trechos relevantes de informações com base na entrada do usuário.
- Integração com Modelos de Linguagem: Resultados da busca são combinados com a pergunta do usuário para gerar respostas precisas.
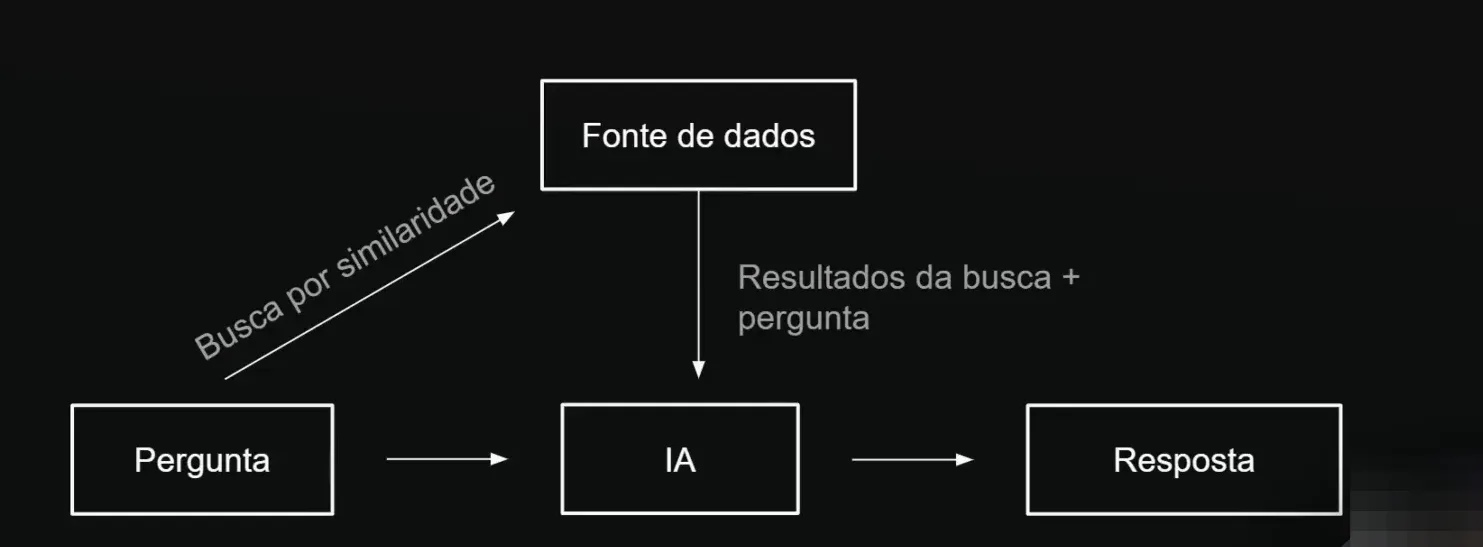
🚀 Como Funciona o Agente RAG?
O agente RAG é uma evolução dos modelos de IA tradicionais. Ele não apenas responde perguntas, mas também interage com fontes de dados externas de maneira inteligente.
Processo de Interação
- O usuário fornece uma pergunta.
- O agente determina se é necessário consultar uma fonte de dados.
- Se necessário, o agente realiza consultas múltiplas à fonte de dados.
- A IA processa as informações e retorna uma resposta ao usuário.
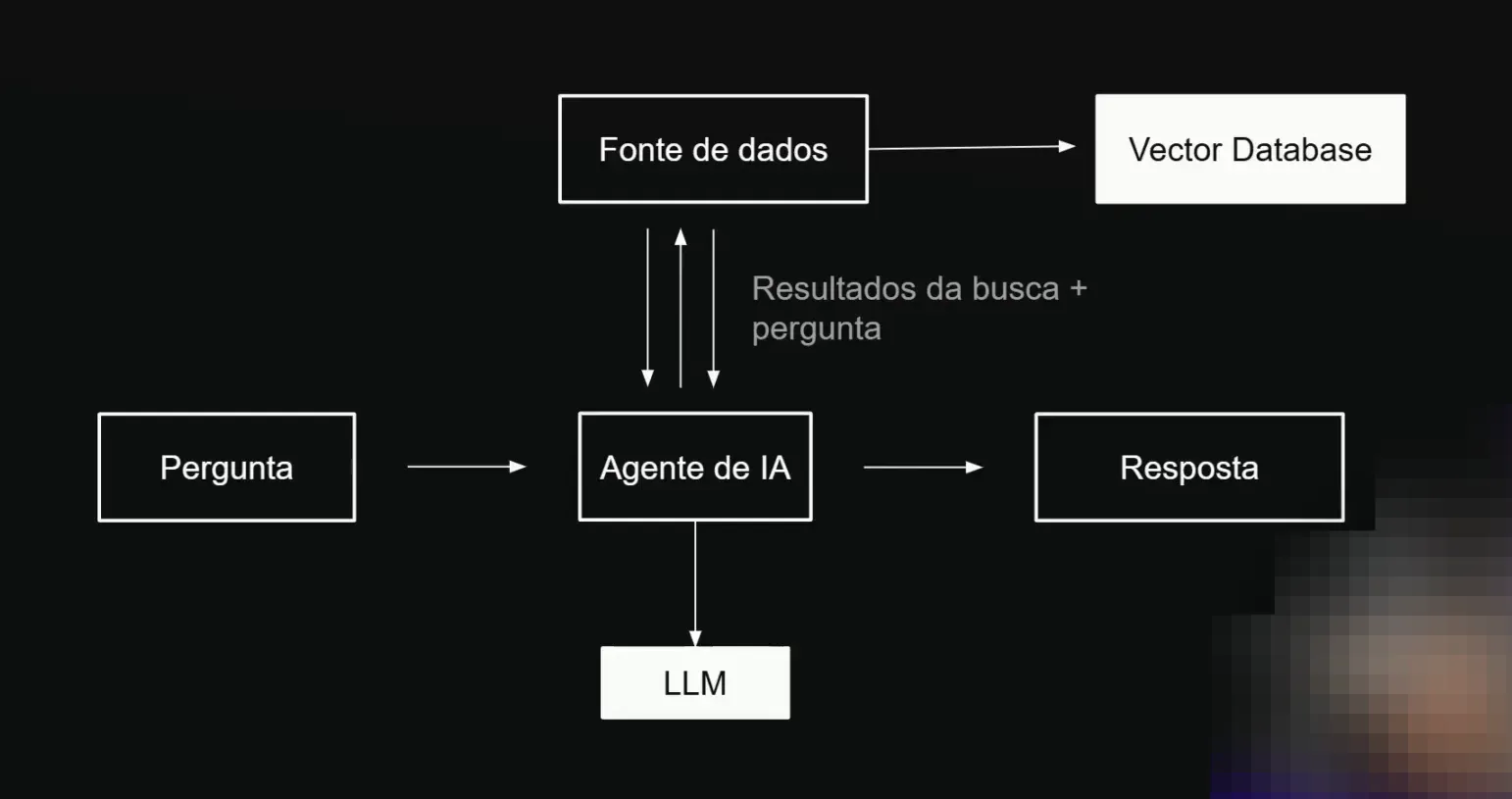
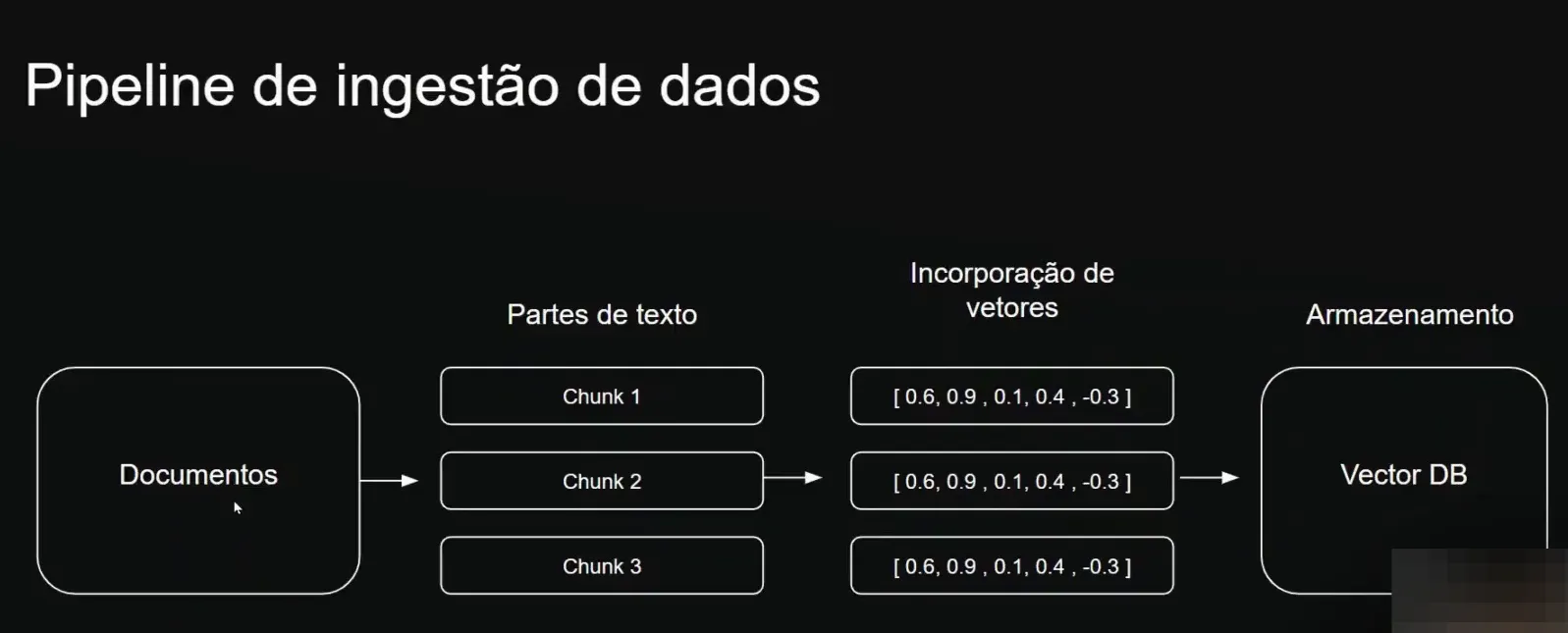
📊 Explorando as Vectodeira Bases
Vamos entender como funcionam as Vectodeira Bases, o local onde armazenamos informações para que sejam pesquisadas pela IA. As Vectodeira Bases, ou bancos de dados vetorizados, são bancos de dados que armazenam vetores.
Um vetor é a representação numérica de uma informação. Isso significa que funciona como traduções matemáticas de informações textuais para um formato que as máquinas conseguem processar e entender.
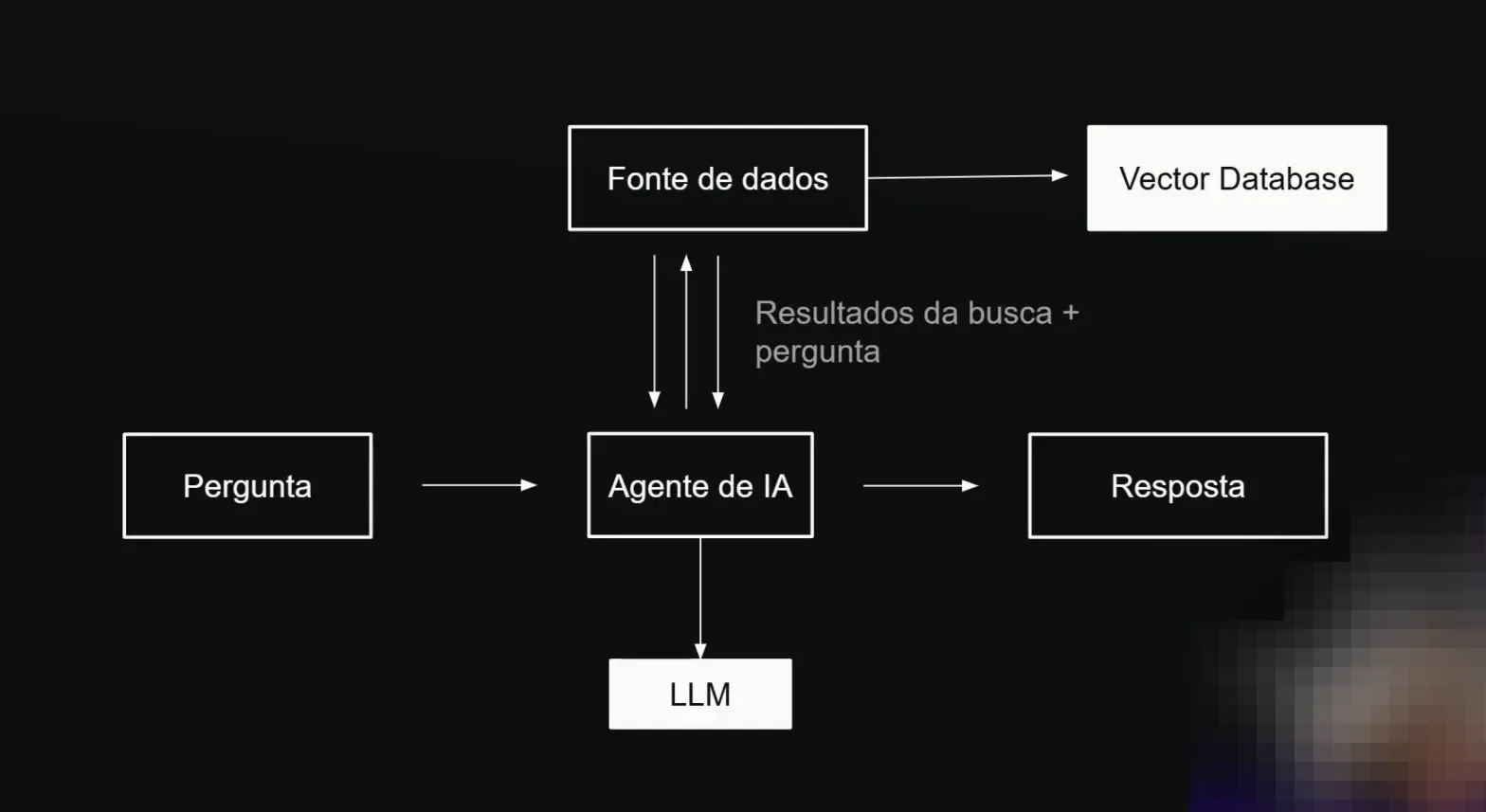
O Que é um Vetor?
Para ilustrar, a palavra “gato” em sua forma matemática poderia ser representada numericamente como 06090. Assim, cada palavra tem sua própria representação vetorial.
Essas representações numéricas permitem que a inteligência artificial entenda características semânticas e relações de significado entre palavras. Isso é fundamental para que a IA possa consultar informações por similaridade semântica.

🗂️ Estrutura das Vector Databases
As Vector Databases funcionam como bibliotecas para armazenar essas representações numéricas. Elas não apenas armazenam, mas organizam os vetores de forma que possam ser pesquisados pela IA.
A estrutura das Vector Databases é sofisticada, permitindo que o agente de IA faça consultas utilizando similaridade semântica, mesmo quando as palavras-chave não são exatamente as mesmas.

Armazenamento Multidimensional
As Vectodeira Bases armazenam informações como um mapa multidimensional. Cada vetor se torna um ponto nesse espaço, onde palavras semanticamente semelhantes estão mais próximas umas das outras.
Isso permite que a busca por similaridade se torne mais inteligente, facilitando a recuperação de informações relevantes para o usuário.
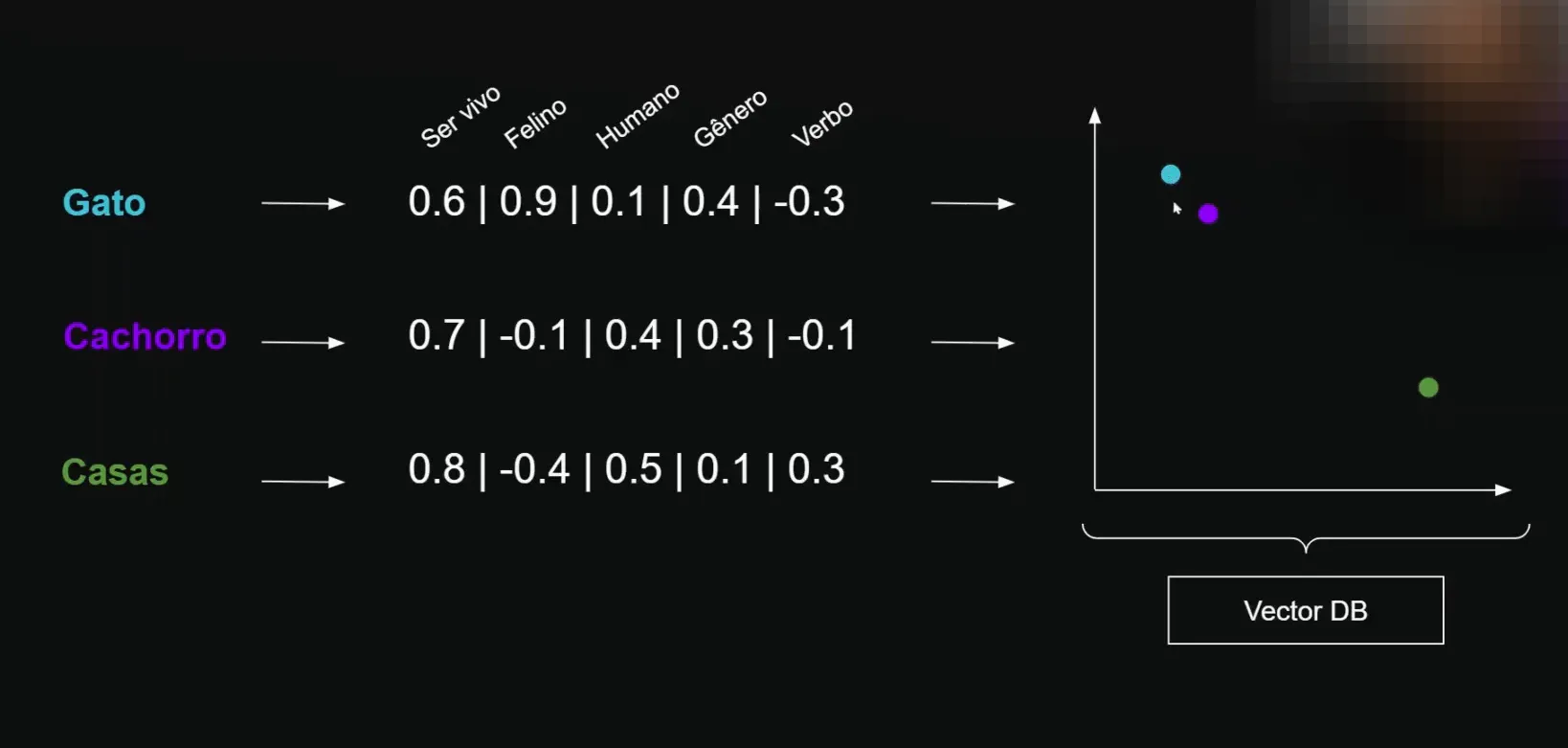
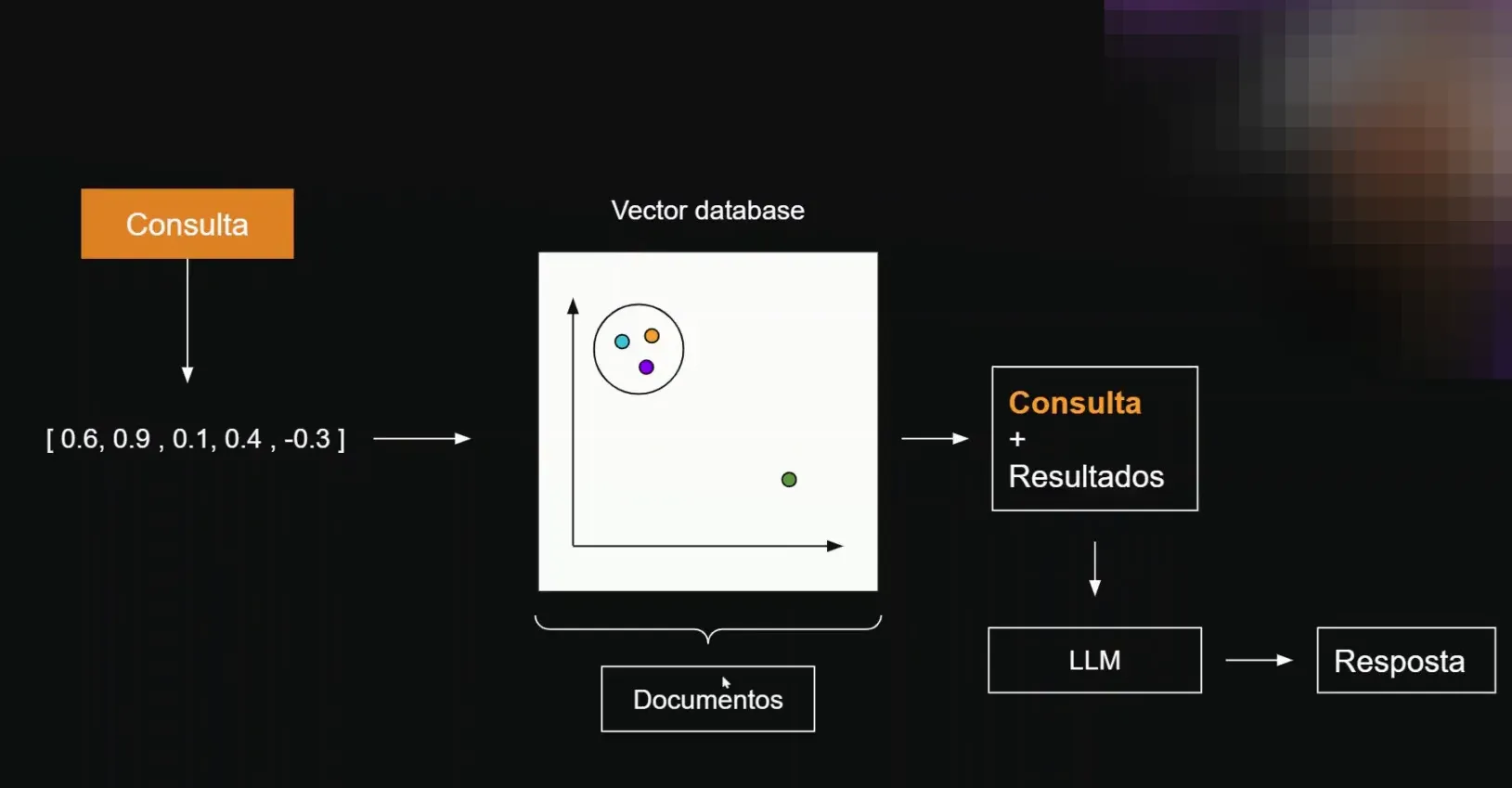
🔄 Fluxo de Consulta do Agente de IA
Quando um usuário faz uma consulta, o agente de IA transforma essa consulta em um vetor. Essa transformação é crucial para a comunicação com a Vector Database.
Após a consulta ser processada, informações que estão dentro do campo semântico similar são recuperadas. Essa consulta é então passada para o modelo de linguagem, que gera uma resposta em linguagem natural.
🏗️ Construindo o Agente de IA
Agora que entendemos os conceitos principais, vamos aplicar o conhecimento na construção do nosso agente de IA. O nosso caso de uso é um agente de IA para suporte técnico de eletrônicos.
Esse agente precisa ser capaz de decidir se é necessário consultar uma fonte de dados adicional. Se necessário, ele deve escolher a melhor fonte e interagir quantas vezes forem necessárias para recuperar todas as informações relevantes.
📥 Etapa de Ingestão de Dados
A primeira etapa no desenvolvimento do nosso agente será a ingestão das informações. Aqui, processaremos e armazenaremos as informações, transformando-as em vetores.
Utilizaremos o Langflow para montar um pipeline de gestão de dados, onde faremos upload de documentos, como manuais de uso em PDF. Esses documentos serão divididos em partes, chamadas de “tianks”, cada uma se tornando um vetor.

⚙️ Configurando o Ambiente Necessário
Para desenvolver nosso agente, precisaremos de algumas ferramentas. No Langflow, você pode optar pela versão auto-hospedada ou criar uma conta gratuita.
Turbine seu Desenvolvimento com Prompts!
Você já sonhou em criar seu próprio aplicativo mas pensou que precisaria ser um gênio da programação? Chegou a hora de transformar esse sonho em realidade! Com as ferramentas no-code de hoje, você pode criar aplicativos profissionais sem escrever uma única linha de código.
Além disso, será necessário criar uma conta no Pinecone, onde armazenaremos nossas informações vetorizadas. O plano Starter é gratuito e suficiente para o nosso projeto.
Por último, uma conta na OpenAI é essencial, pois usaremos seu modelo para vetorizar as informações.
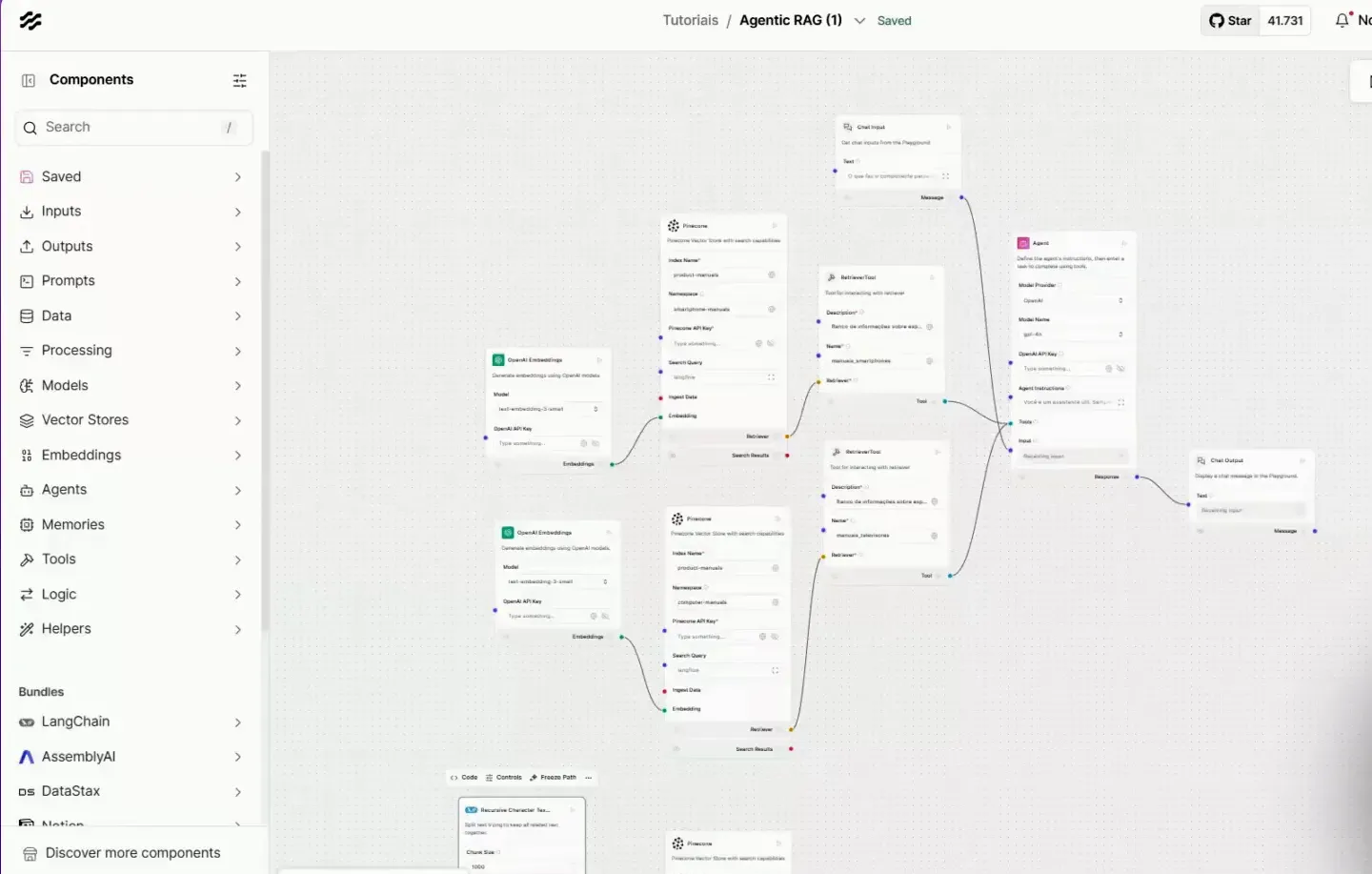
🔗 Construindo o Pipeline de Dados
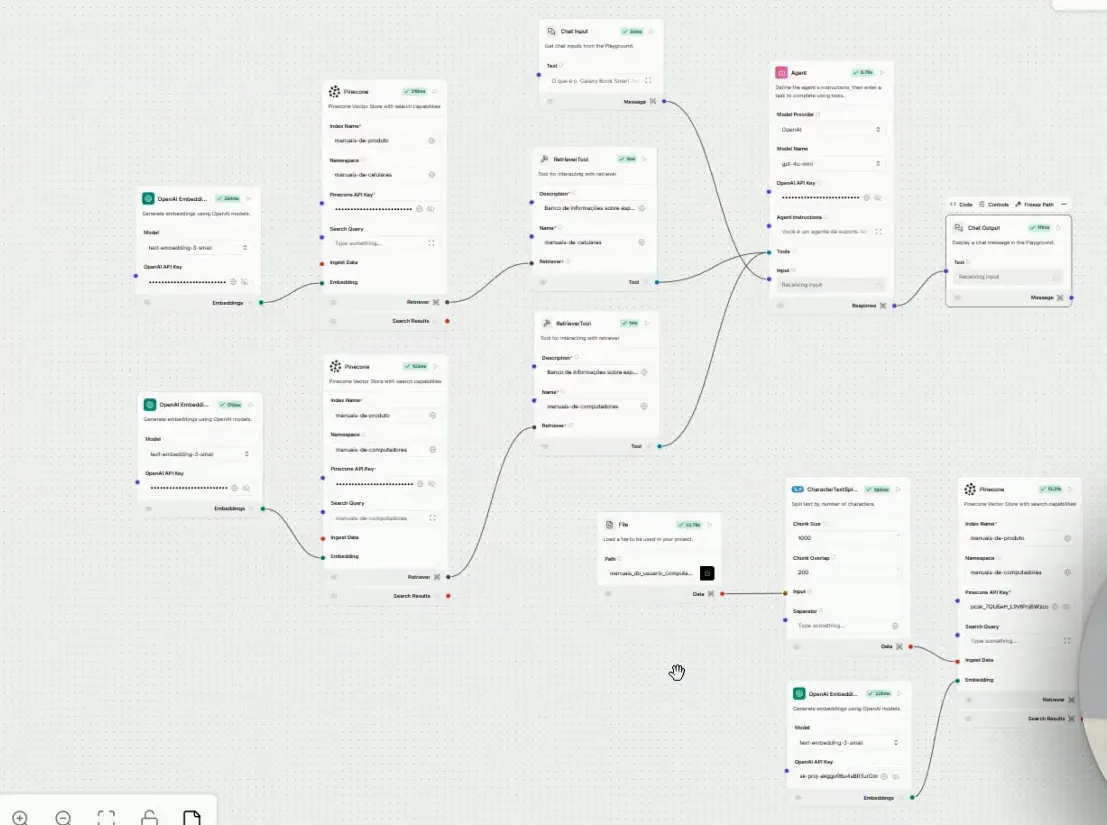
Com as ferramentas configuradas, começamos a construir o pipeline de dados no Langflow. O processo de ingestão envolverá a divisão dos documentos em “tianks” e a vetorização utilizando o modelo da OpenAI.
Após a vetorização, essas informações serão armazenadas no Pinecone, prontas para serem consultadas pelo agente de IA.
📂 Dividindo Documentos em Tanques
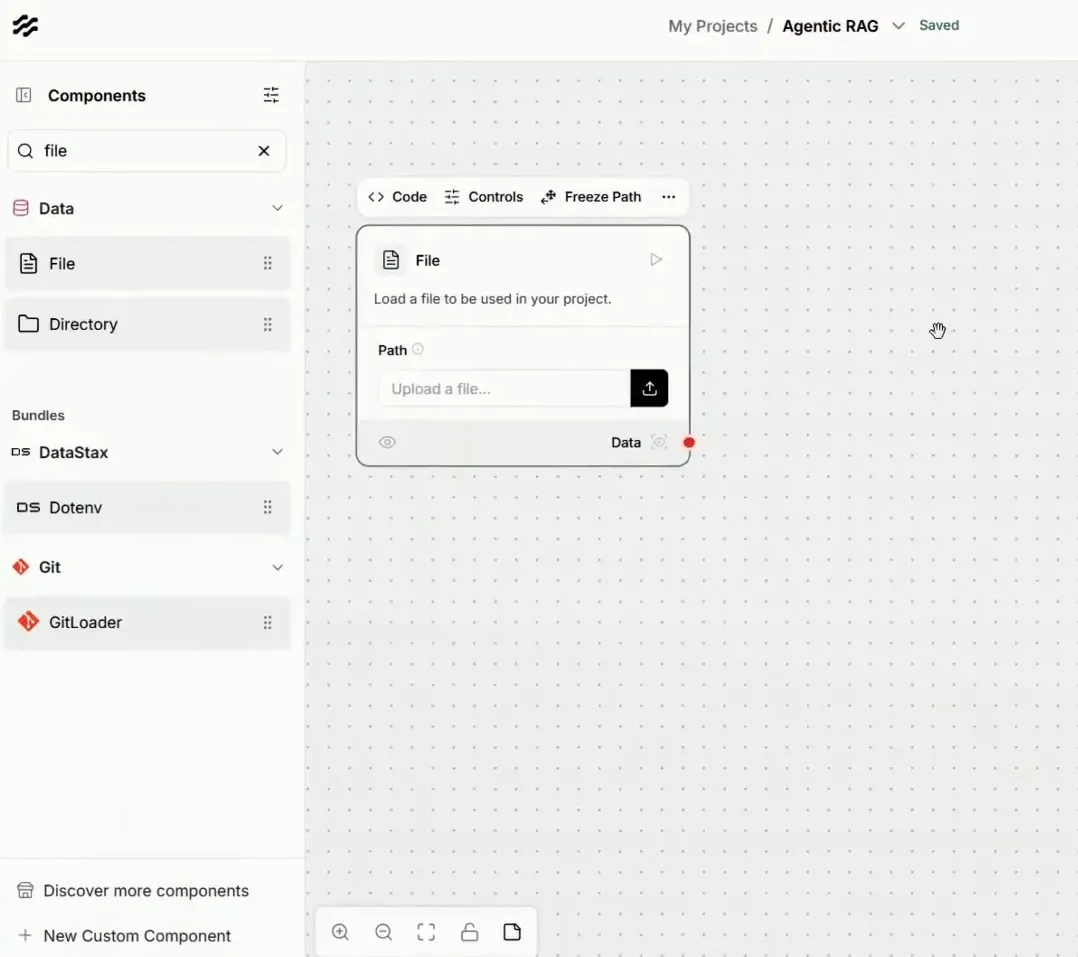
O primeiro passo no nosso fluxo é o upload das informações. Para isso, utilizamos o componente de file, que permite que documentações sejam carregadas no projeto. Esse componente extrai dados dos PDFs, preparando-os para a próxima etapa.
Após o upload, precisamos dividir as informações em tanques. Para isso, arrastamos o componente de Splitter para a tela. Esse componente é responsável por segmentar os dados extraídos em partes menores, facilitando o processamento posterior.
Os parâmetros do Splitter incluem o tamanho do chunk, que por padrão será de mil caracteres. O parâmetro de overlap, que eu vou explicar mais adiante, é crucial para manter o contexto entre os chunks.
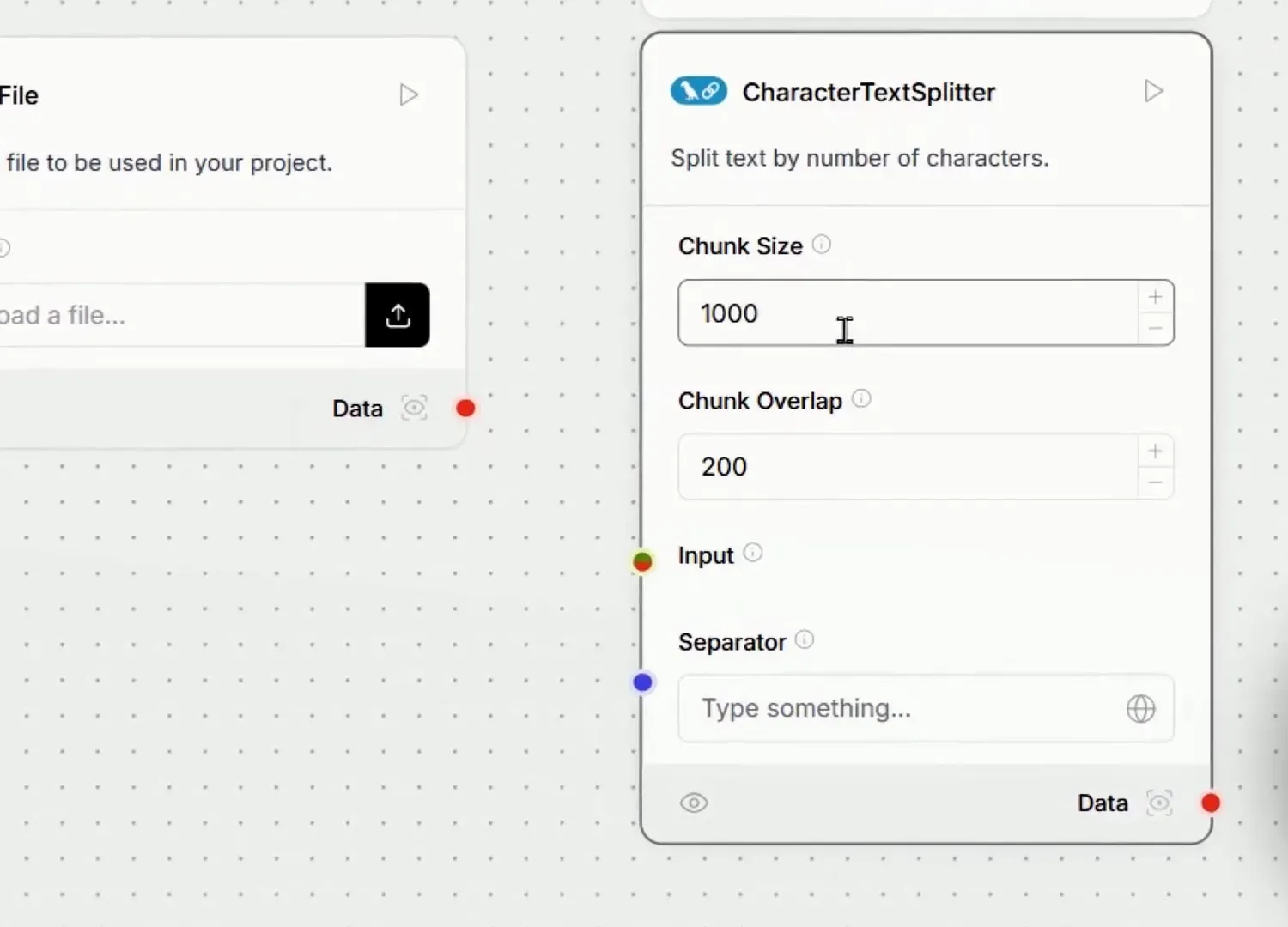
O que São Chunks?
Os chunks são partes das documentações que serão processadas. Ao dividirmos a documentação, cada parte terá um tamanho definido, permitindo que a IA compreenda melhor os dados. O overlap entre os chunks garante que o contexto não se perca na divisão.
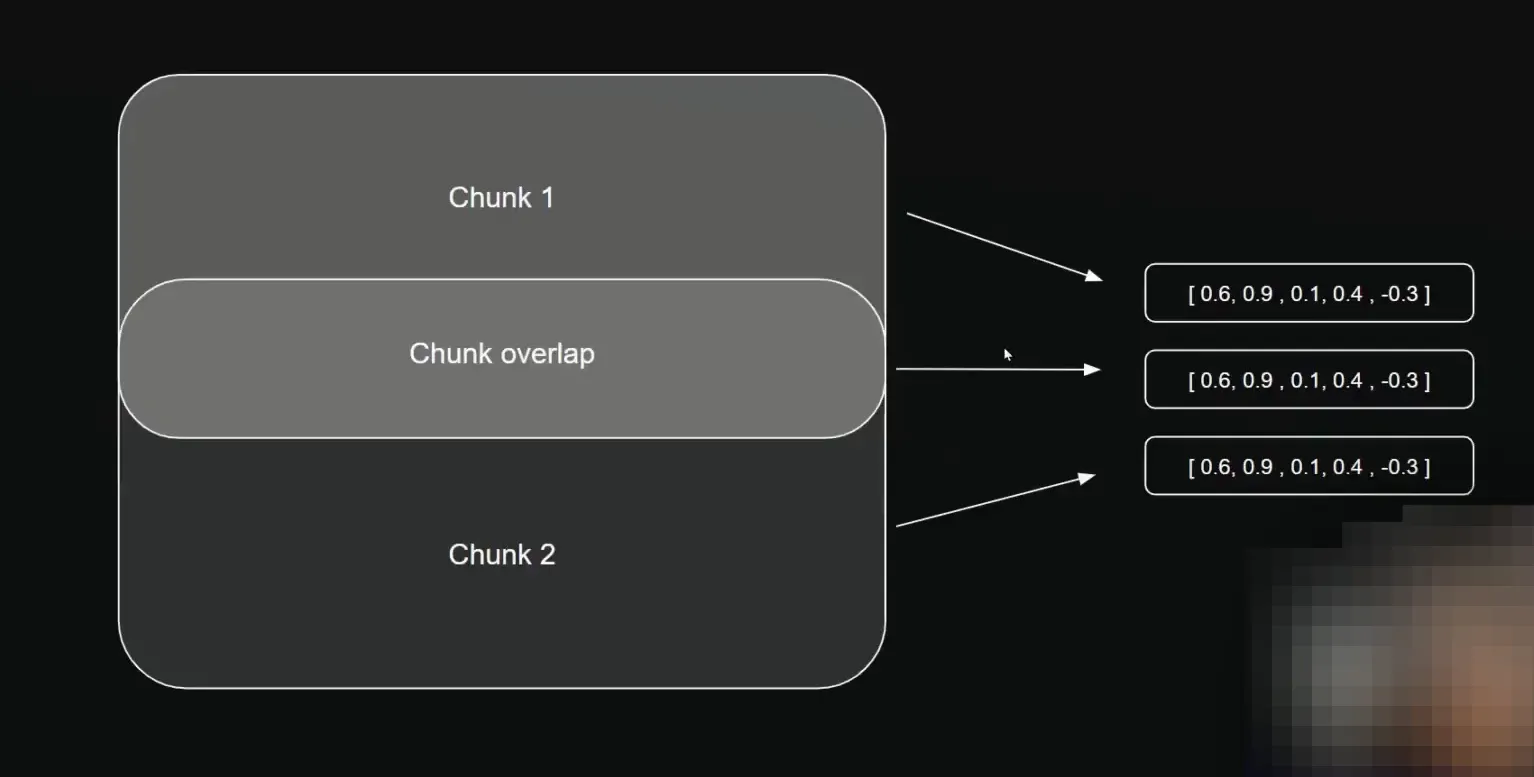
Após definir o tamanho dos chunks e o overlap, a próxima etapa é enviar essas informações para a Vector Database, que no nosso caso será o Pinecone.
🔗 Integrando com o Pinecone
Agora, vamos integrar nossos dados ao Pinecone. Arrastamos o componente correspondente à Vector Store e conectamos ao fluxo. O Pinecone funcionará como um repositório para armazenar as informações vetorizadas.
Os parâmetros do Pinecone incluem o index, que atua como uma pasta para segmentar as informações. No nosso caso, teremos namespaces distintos para manuais de celulares e computadores, permitindo uma organização eficiente.
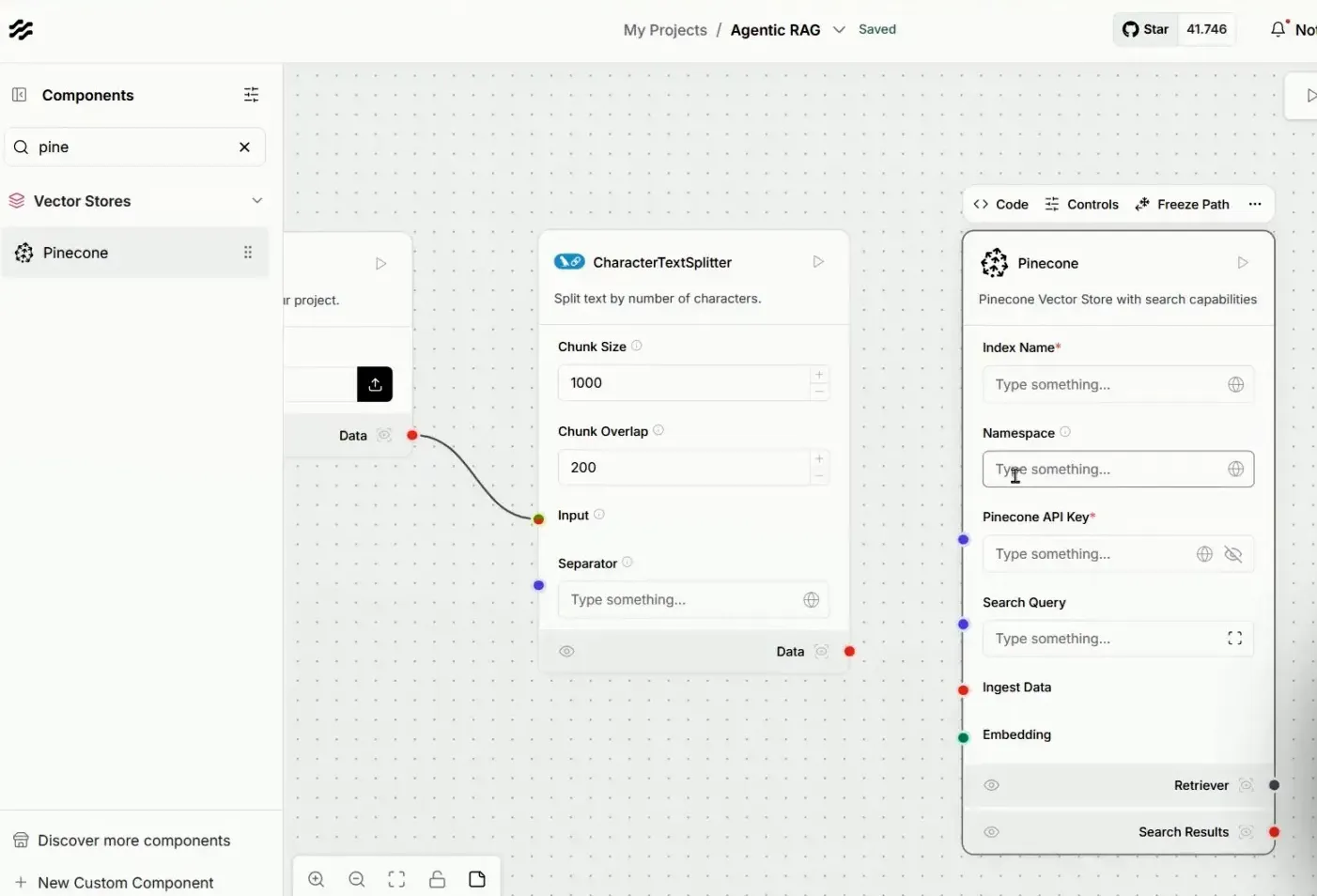
Além disso, precisamos de uma chave de API para estabelecer a conexão entre o Langflow e o Pinecone. É essencial que essa chave esteja configurada corretamente para garantir que os dados sejam armazenados sem problemas.
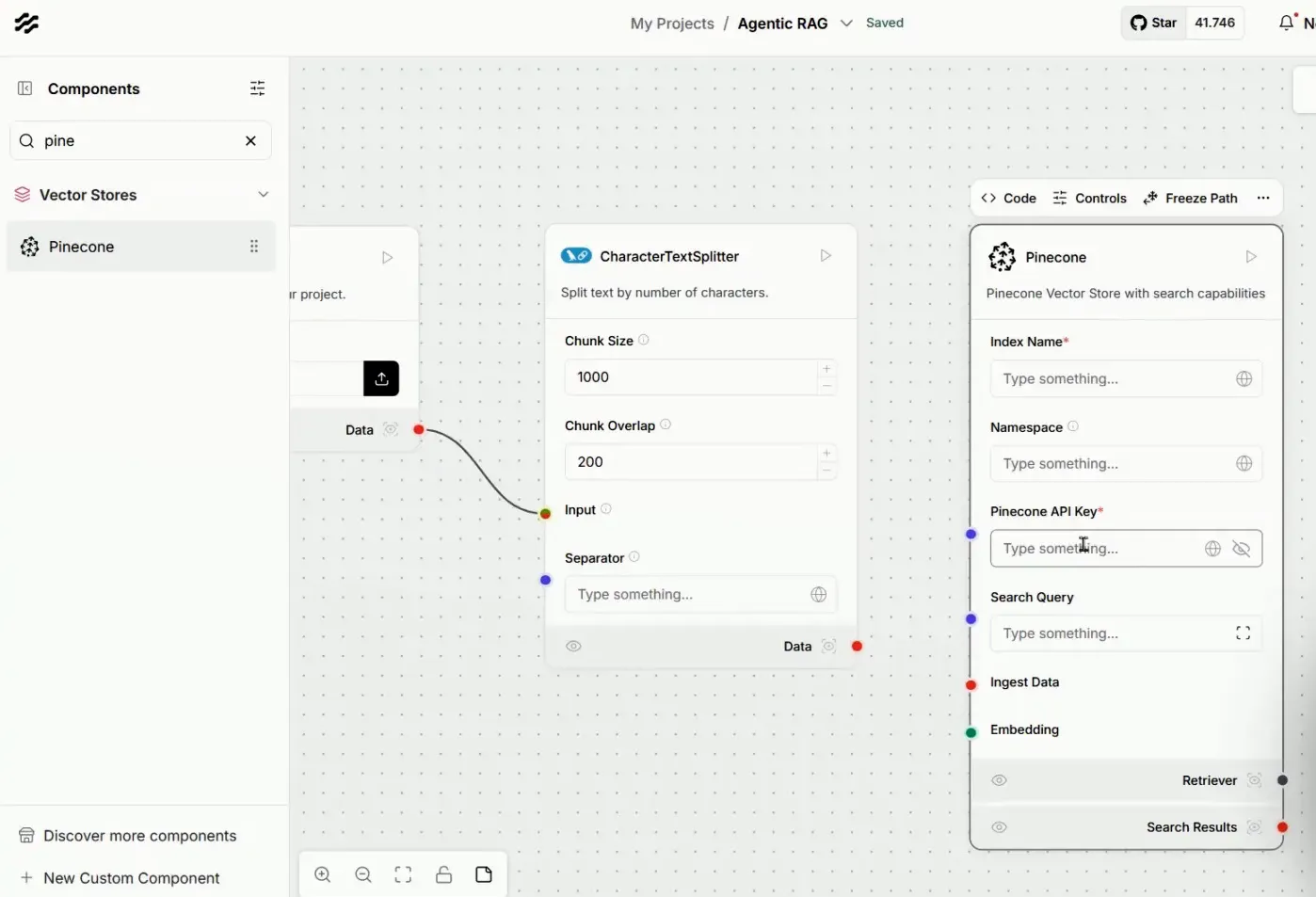
⚙️ Finalizando a Configuração do Agente
Com as integrações feitas, vamos finalizar a configuração do nosso agente. Precisamos garantir que todos os parâmetros estejam preenchidos corretamente, especialmente o nome do index que criamos no Pinecone.
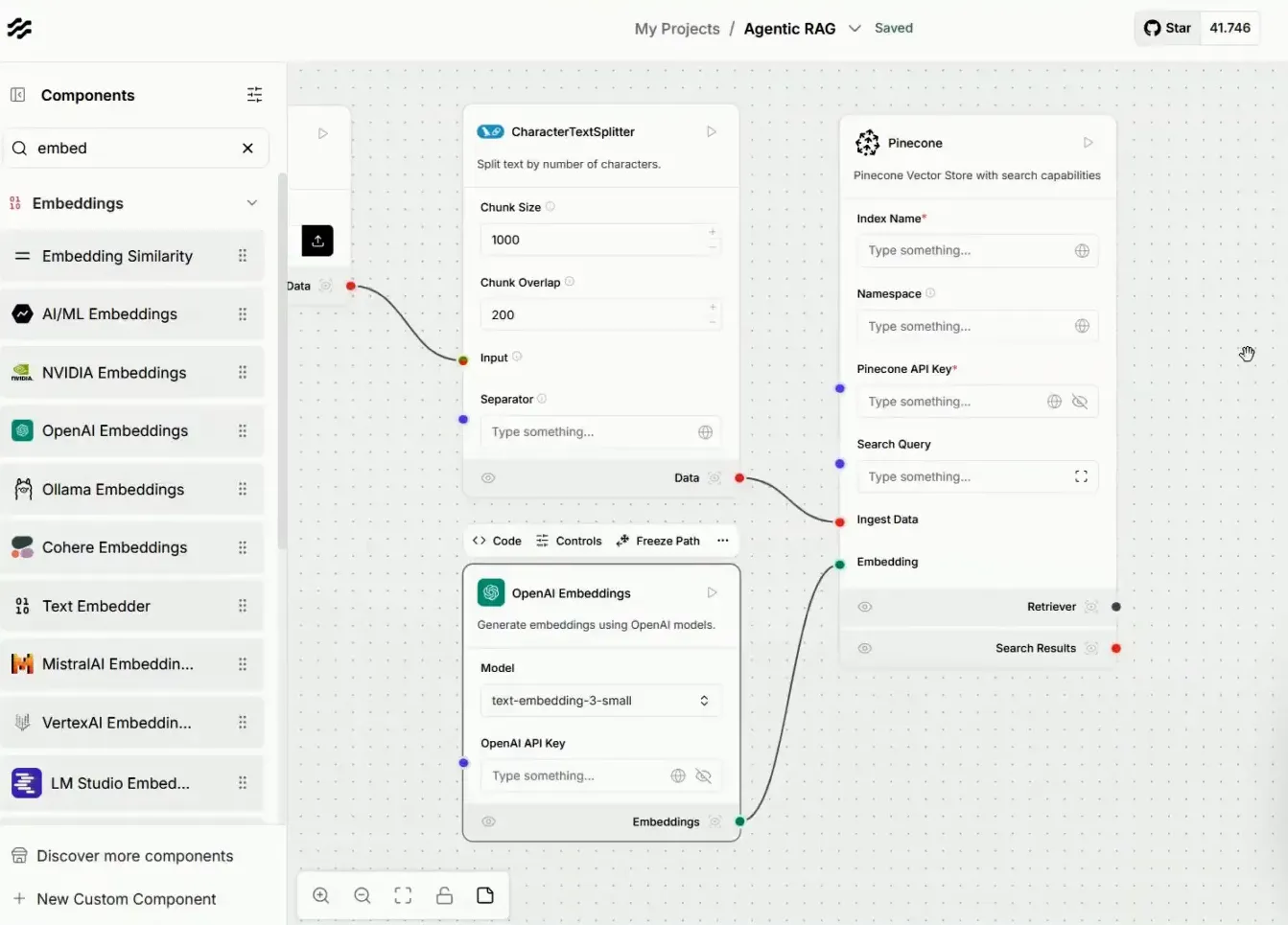
Após preencher os parâmetros, vamos realizar o upload das informações que queremos ingerir. O processo de ingestão atualizará o index existente e criará novos namespaces conforme necessário.
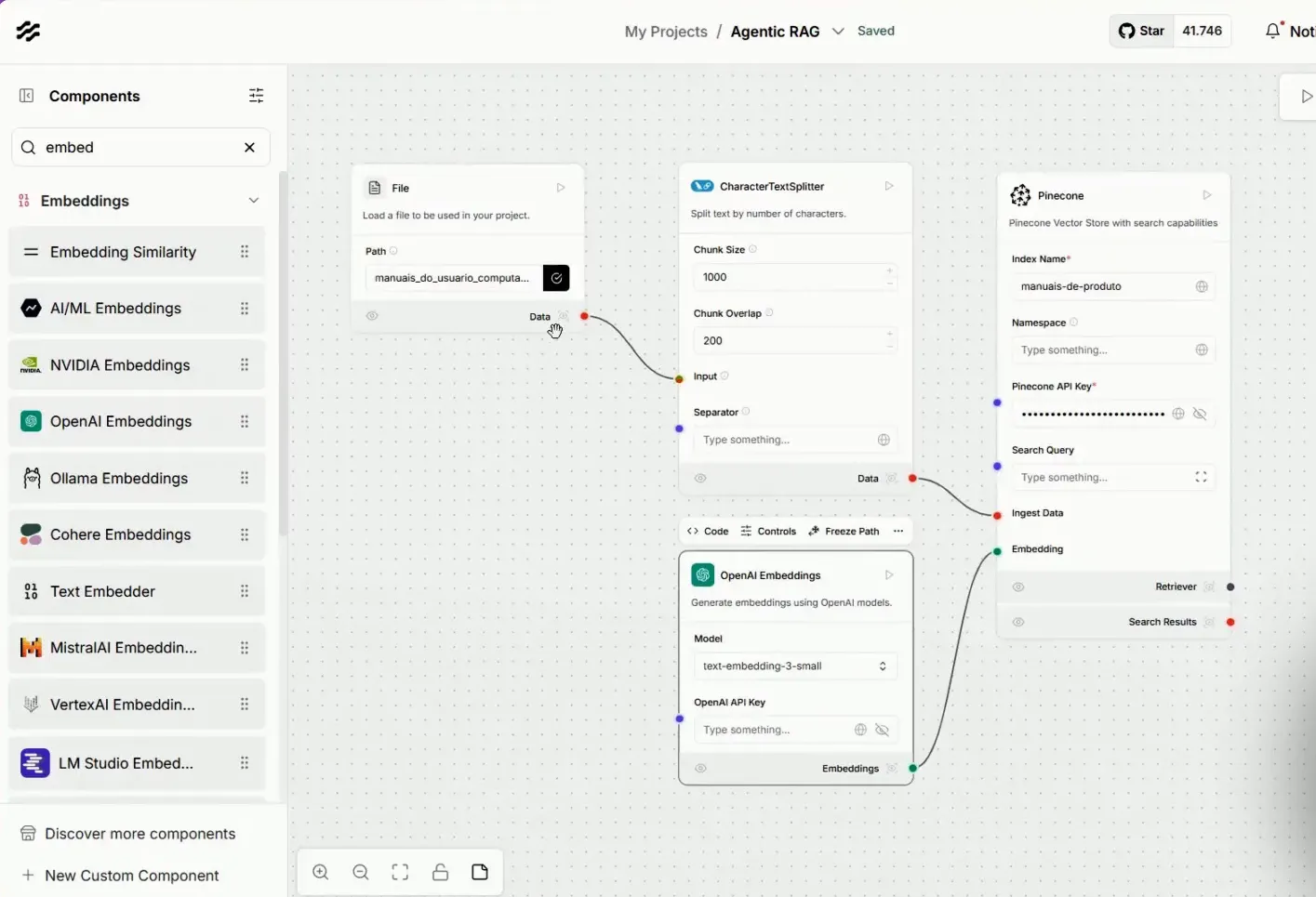
🔄 Fluxo de Recuperação de Dados
Agora que temos as informações armazenadas, é hora de construir o fluxo de recuperação. Este fluxo permitirá que o usuário interaja com o agente através de um chat input, onde as perguntas serão capturadas.
O próximo passo é integrar o componente do agente, que será responsável por processar as perguntas e consultar os dados armazenados. Precisamos configurar o modelo da OpenAI e as instruções do agente para garantir uma resposta precisa.
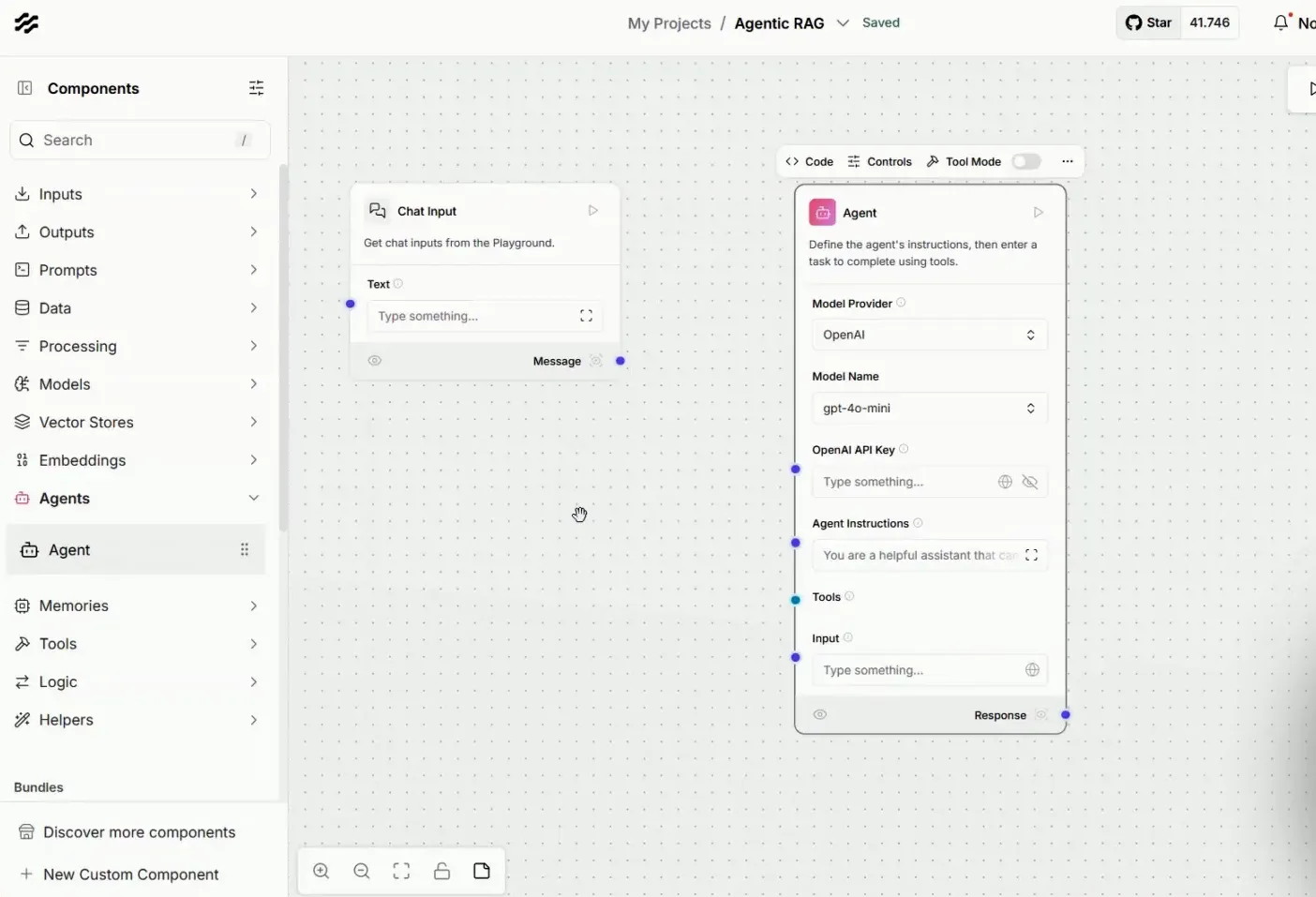
🧪 Testando o Agente de IA
Com o fluxo de recuperação finalizado, vamos testar o agente. Faremos perguntas sobre os manuais de celulares e computadores para verificar se o agente consegue acessar as informações corretamente.
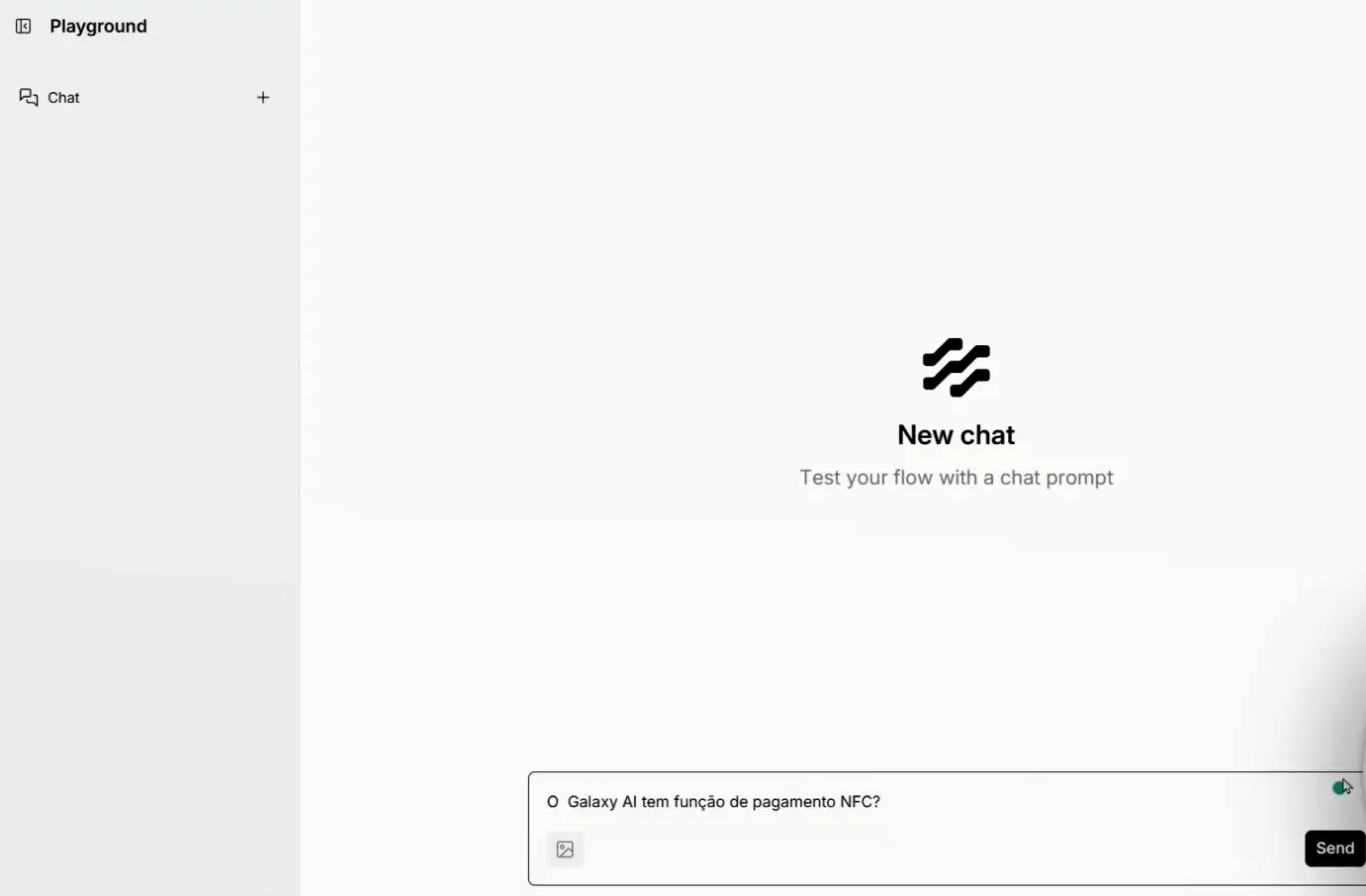
Durante os testes, o agente deve demonstrar a capacidade de identificar a fonte correta de dados e retornar respostas detalhadas. Esse processo é fundamental para validar a eficácia do agente em situações do mundo real.
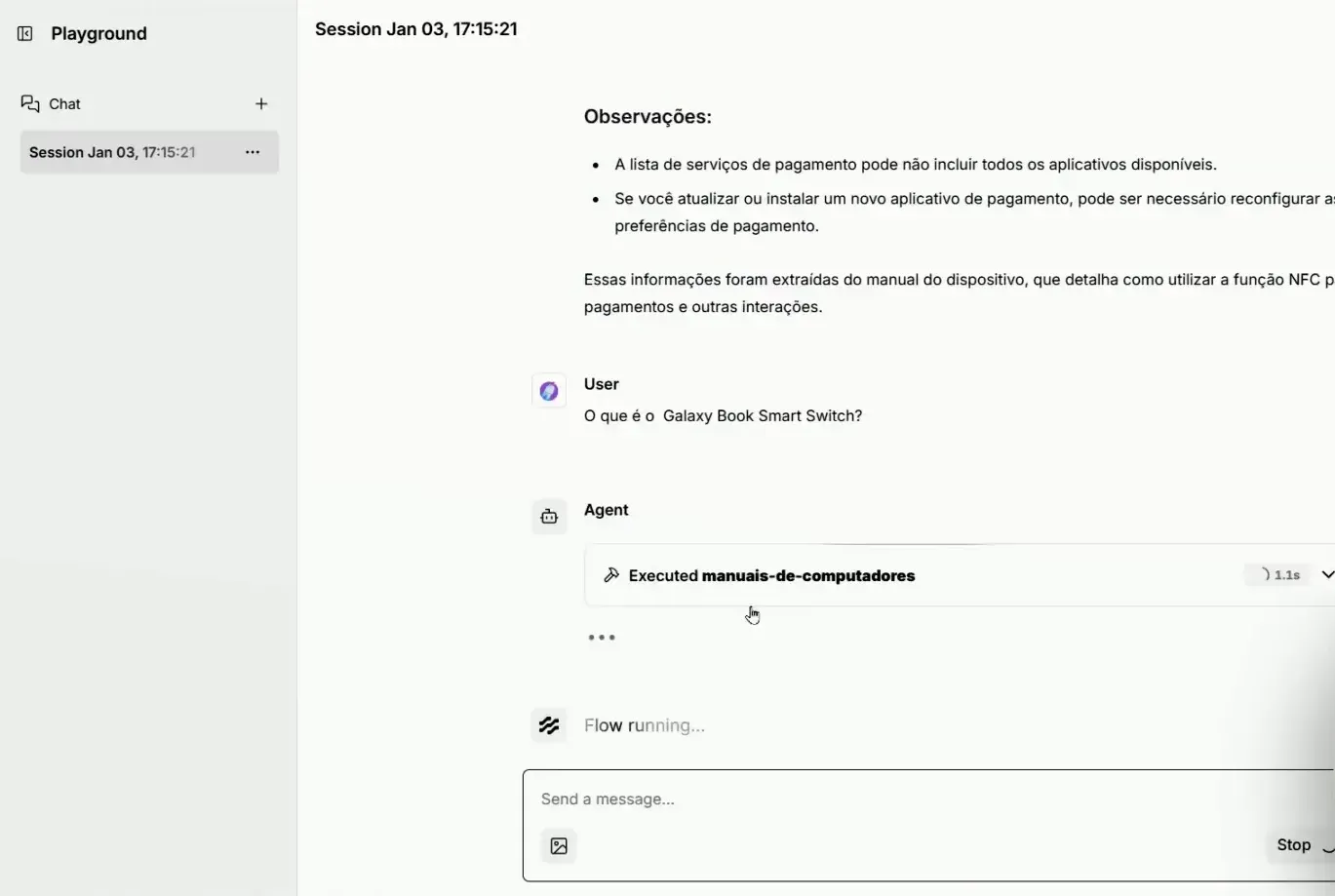
📌 Considerações Finais e Expansões Futuras
Com nosso agente de IA configurado e testado, podemos refletir sobre as possibilidades de expansão. O modelo inicial que desenvolvemos pode ser aprimorado com novos componentes e ajustes nos parâmetros para melhorar a eficiência e a precisão.
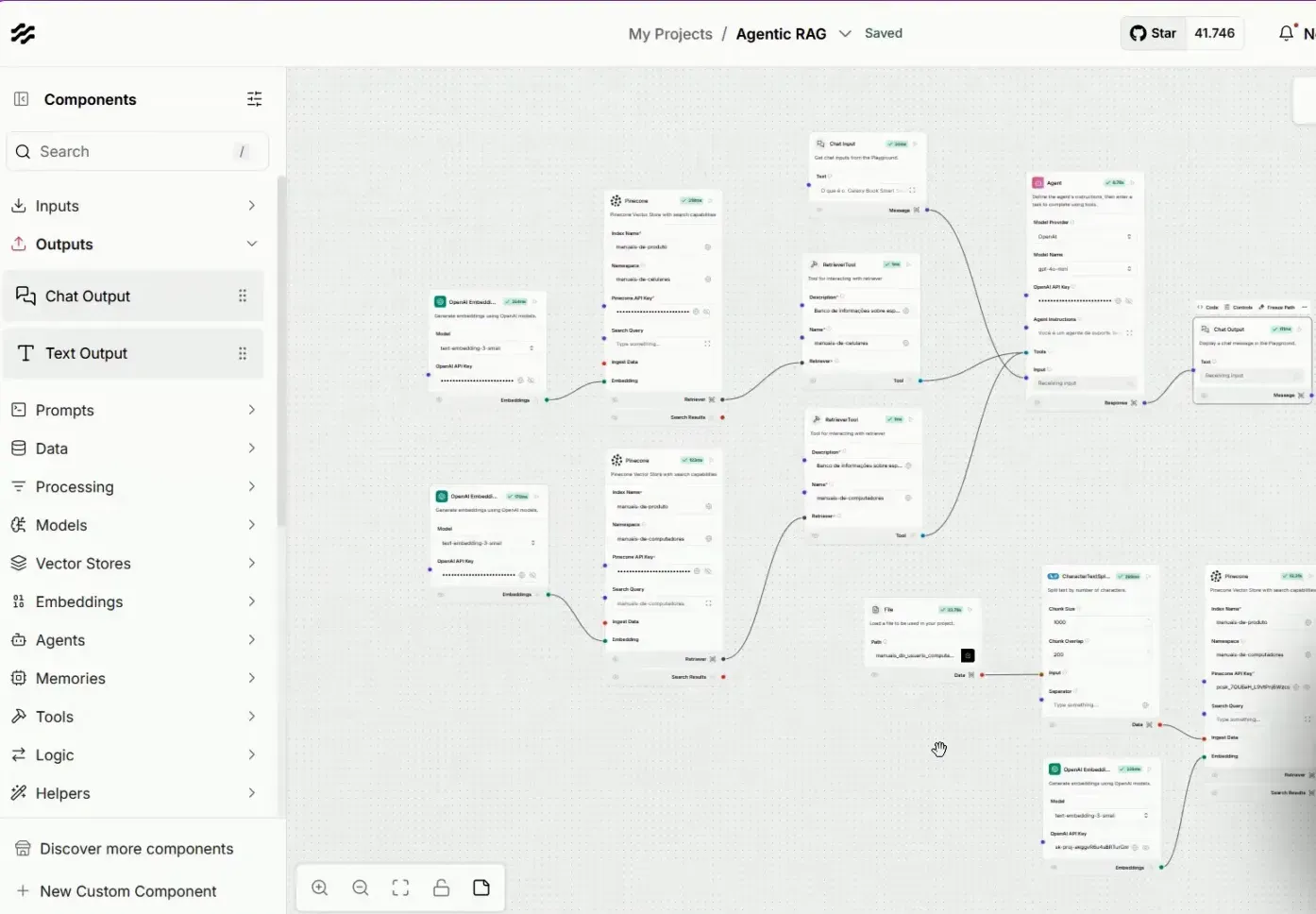
Além disso, a adição de novos namespaces e a atualização de informações existentes são processos que podem ser facilmente implementados, permitindo que o agente se mantenha relevante e atualizado com as últimas informações disponíveis.
❓ FAQ
1. O que é um agente RAG?
Um agente RAG (Retrieval-Augmented Generation) combina a geração de linguagem com a recuperação de informações, permitindo respostas mais precisas e contextuais.
2. Como funciona a divisão em chunks?
A divisão em chunks permite que as informações sejam processadas em partes menores, mantendo a relação entre elas através do overlap.
3. O que é o Pinecone?
Pinecone é uma Vector Database que armazena informações vetorizadas, facilitando consultas rápidas e eficientes.
4. É necessário programar para usar o Langflow?
Não, o Langflow permite criar fluxos de trabalho sem necessidade de programação, facilitando o desenvolvimento de agentes de IA.
5. Como posso expandir meu agente?
Você pode adicionar novos namespaces, ajustar parâmetros e incluir novos componentes para melhorar a funcionalidade do agente.
Autor
flpchapola@hotmail.com
Posts relacionados

DSPy na prática: programação declarativa com LLMs
O DSPy transforma a forma como lidamos com prompts ao permitir a definição de assinaturas em Python para otimização automática de LLMs....

Quando programar vira prompt: o fim da era do código
A programação evoluiu com a IA, transformando-se de escrita manual de código para um processo de orquestração de prompts. Isso levanta questões...

Quando programar vira prompt: o fim da era do código
A programação evoluiu com a IA, transformando-se de escrita manual de código para um processo de orquestração de prompts. Isso levanta questões...

Como o Cursor transformou meu fluxo de desenvolvimento
O Cursor uniu editor, agentes e automações: planos rastreáveis (.cursor/plans/), Rules & Skills, cloud agents em cursor.com/agents, Debug Mode e comandos (/pr,...

A Revolução Silenciosa: Como a Anthropic e a Bun Estão Transformando o Desenvolvimento de Software com IA
Em 2025, a Anthropic consolidou sua estratégia de dominar a infraestrutura de desenvolvimento de software ao adquirir a Bun, uma startup com...
- Agentes de IA
- AI coding infrastructure
- AI software development
- Anthropic acquires Bun
- Anthropic market strategy
- Automação
- Bun JavaScript runtime
- Bun startup performance
- Claude Code
- Claude Code growth
- Codificação
- desenvolvedores
- Desenvolvimento
- desenvolvimento de software
- Generative AI trends
- Git
- IA
- Inovação
- Integração de IA
- Inteligência Artificial
- Inteligência artificial integrada
- Microsoft Nvidia investment
- OpenAI
- produtividade
- Software automation tools
- Soluções
- Tecnologia
- Tendências de IA

Como Usar Windsurf e Lovable para Criar Landing Pages que Convertem 100% GRÁTIS
Quero mostrar um fluxo prático e reproduzível para criar uma landing page de captura de leads que funcione de verdade, totalmente sem...
Leia tudo