Neste artigo, vamos explorar como a inteligência artificial está transformando o desenvolvimento frontend e o design AI através do uso de Agentic RAG. Aprenda a criar soluções dinâmicas que utilizam múltiplas fontes de informação para otimizar a experiência do usuário.
Índice
- Início 🚀
- RAG vs. Agentic RAG 🤖
- Overview da solução 🌐
- Criando um Vector DB no DataStax Astra 📊
- Criando collection para armazenar embeddings 📦
- Carregando dados com DataStax Langflow 📥
- Criando o Agente no Langflow 🤖
- Criando as Tools 🛠️
- Executando o Agente no Playground do Langflow 🛠️
- Monitoramento da Execução 📊
- Próximos Passos no Desenvolvimento 🚀
- FAQ sobre Agentic RAG e AI ❓
Início 🚀
A inteligência artificial está mudando a forma como interagimos com dados e informações. No desenvolvimento frontend, a combinação de diferentes fontes de dados é crucial. Aqui, vamos explorar como utilizar a técnica de RAG (Retrieval-Augmented Generation) e sua versão mais avançada, o Agentic RAG, para criar aplicações dinâmicas e responsivas.
RAG vs. Agentic RAG 🤖
O RAG é uma técnica poderosa que combina a recuperação de informações com geração de texto. Enquanto o RAG tradicional se baseia em um modelo que busca informações de uma única fonte, o Agentic RAG expande essa capacidade. Ele permite que o agente escolha entre múltiplas origens de dados, tornando a resposta mais contextualizada e relevante.
- RAG: Busca informações de uma única fonte de dados.
- Agentic RAG: Seleciona dinamicamente a origem mais relevante dentre várias disponíveis.
Essa flexibilidade é essencial para aplicações que lidam com informações complexas e variadas, como documentos, textos e dados de diferentes formatos.
Overview da solução 🌐
A solução que vamos implementar utiliza um banco de dados vetorial para armazenar e recuperar informações relevantes. O fluxo de trabalho será dividido em duas partes principais: carga de dados e recuperação de dados.
- Carga de Dados: Carregamos documentos, que serão divididos em partes menores (chunks) e transformados em embeddings.
- Recuperação de Dados: Utilizamos um agente para determinar qual coleção de dados utilizar com base na pergunta do usuário.
Essa abordagem não apenas melhora a precisão das respostas, mas também enriquece a experiência do usuário ao fornecer informações mais contextuais.
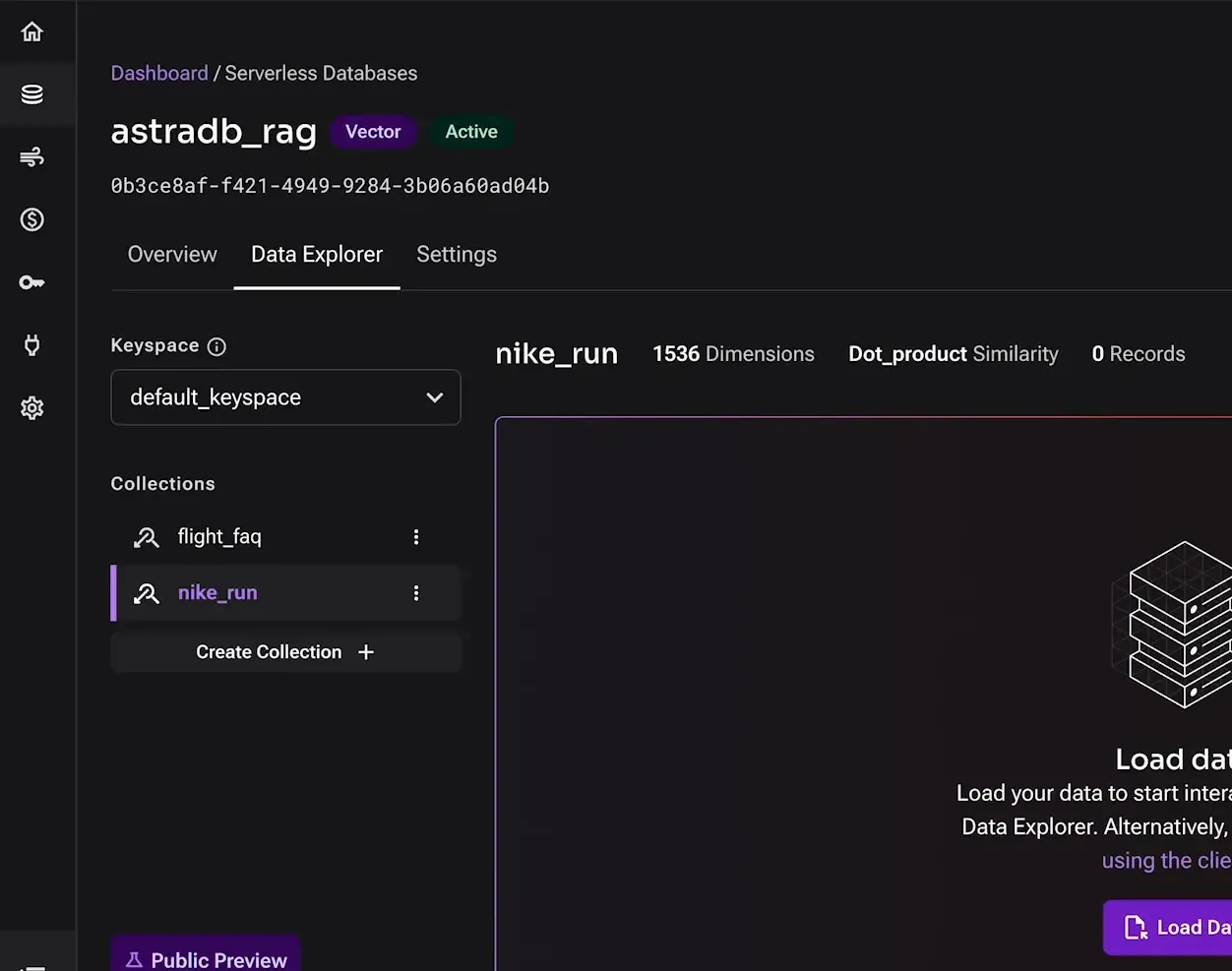
Criando um Vector DB no DataStax Astra 📊
Para implementar nossa solução, começaremos criando um banco de dados vetorial no DataStax Astra. O processo é simples e direto. Aqui está um passo a passo:
- Criar o Banco de Dados: Acesse o DataStax Astra e crie um novo banco de dados. Escolha a região que melhor se adapta à sua aplicação.
- Criar Coleções: Crie coleções para armazenar diferentes tipos de dados. Por exemplo, uma coleção para informações sobre voos e outra para documentos sobre eventos.
- Configurar Dimensões: Defina o número de dimensões para os embeddings. Uma configuração comum é de 1536 dimensões, utilizando a métrica de similaridade dot product.

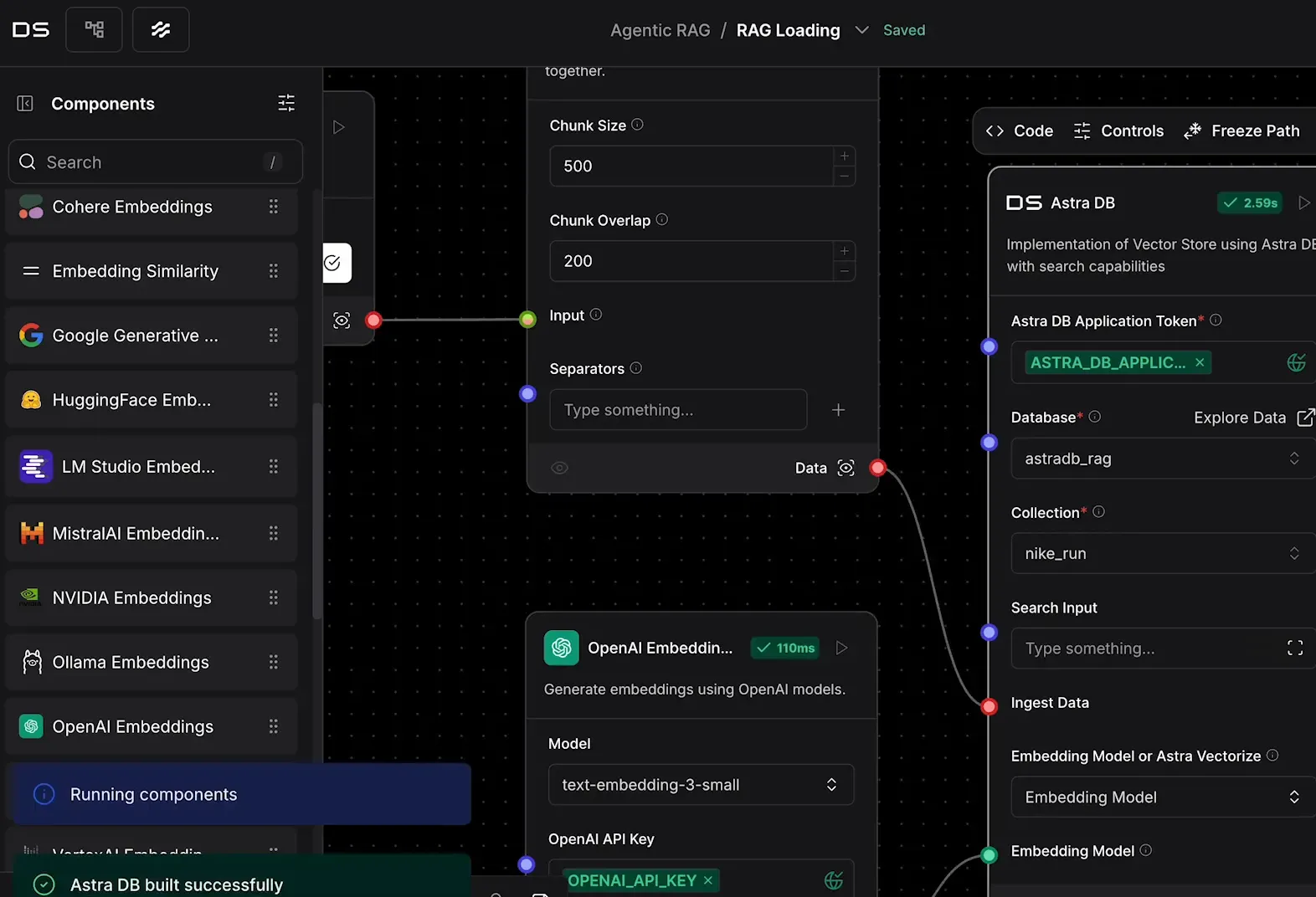
Após criar as coleções, vamos carregar os dados. Para isso, utilizaremos o Landing Flow, uma ferramenta que facilita a ingestão e o processamento dos dados.
Com o Landing Flow, você pode criar fluxos que automatizam a carga dos documentos. Os dados serão divididos em partes menores e armazenados no banco de dados vetorial. Vamos agora detalhar como fazer isso.
- Selecionar os Arquivos: Escolha os documentos que deseja carregar.
- Definir o Tamanho dos Chunks: Ajuste o tamanho das partes conforme a necessidade. Para documentos menores, partes menores funcionam melhor.
- Executar o Fluxo: Após configurar, execute o fluxo e verifique se os dados foram carregados corretamente.
Uma vez que os dados estejam carregados, você pode começar a implementar o agente que irá utilizar essas informações para responder perguntas do usuário. O próximo passo é configurar o fluxo de recuperação, onde o agente decidirá qual coleção usar com base na consulta.
O uso da inteligência artificial no desenvolvimento frontend, especialmente com a abordagem de Agentic RAG, permite que suas aplicações sejam mais responsivas e personalizadas. Com a combinação de várias fontes de dados e a capacidade de selecionar informações relevantes, você pode criar experiências de usuário mais ricas e informativas.
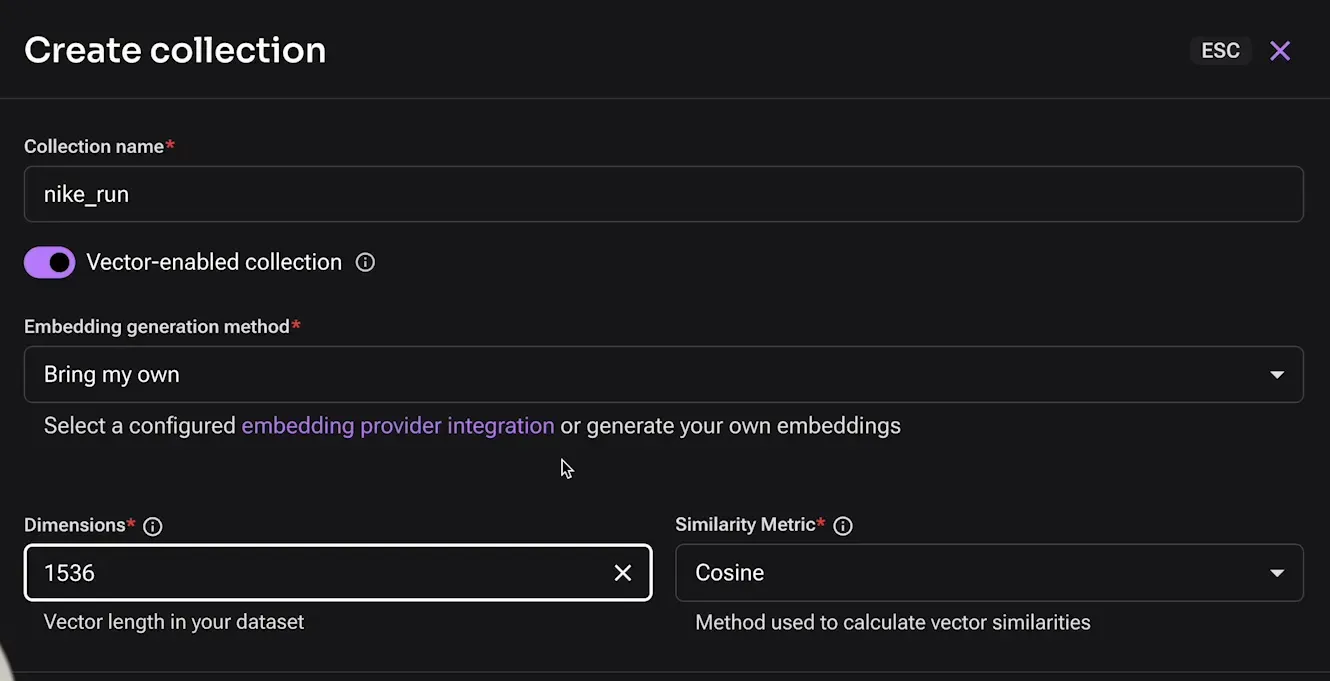
Criando collection para armazenar embeddings 📦
Para armazenar os embeddings gerados a partir dos documentos carregados, precisamos criar coleções específicas dentro do nosso banco de dados. Isso garante que os dados estejam organizados e otimizados para recuperação posterior.
Vamos seguir um passo a passo para criar as coleções no DataStax Astra:
- Acessar o DataStax Astra: Entre na sua conta do DataStax Astra e selecione o banco de dados que você criou anteriormente.
- Criar a primeira coleção: Clique em “Create Collection” e nomeie-a, por exemplo, “Voos”. Defina que esta coleção usará vetores e escolha o número de dimensões, como 1536, utilizando a métrica de similaridade dot product.
- Criar a segunda coleção: Repita o processo para a coleção de “Corridas”, garantindo que ambas as coleções tenham a mesma configuração de dimensões e métrica.
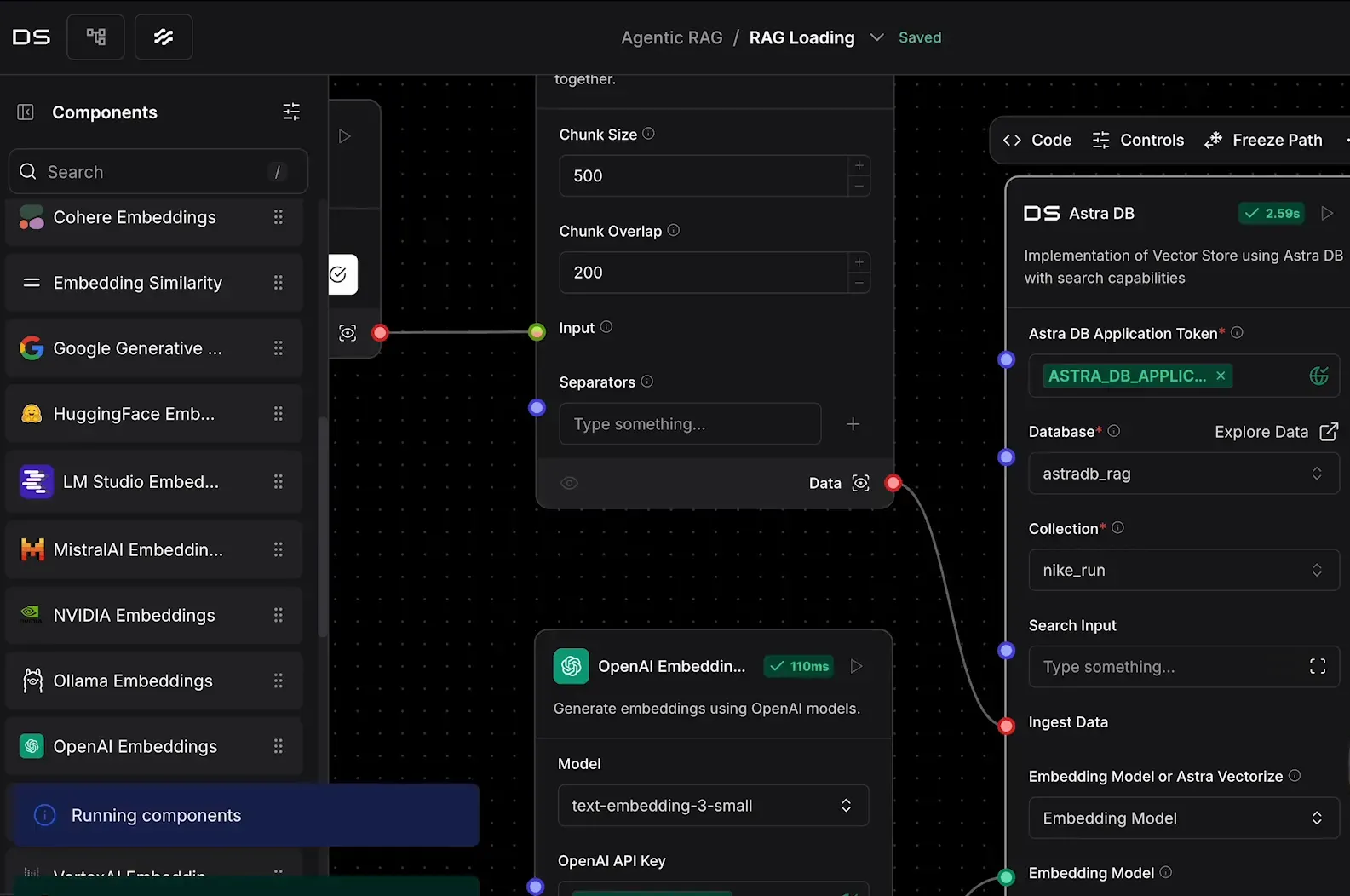
Carregando dados com DataStax Langflow 📥
Agora que temos nossas coleções criadas, vamos utilizar o DataStax Langflow para carregar os dados. O Langflow facilita o processo de ingestão e processamento de documentos.
Os passos para carregar os dados são:
- Selecionar o arquivo: Escolha o documento que deseja carregar, como um PDF ou um arquivo de texto.
- Definir o tamanho dos chunks: Ajuste o tamanho dos chunks, com tamanhos menores para documentos menores, garantindo que cada parte seja significante.
- Executar o fluxo: Após configurar, execute o fluxo e verifique se os dados foram carregados corretamente nas coleções apropriadas.
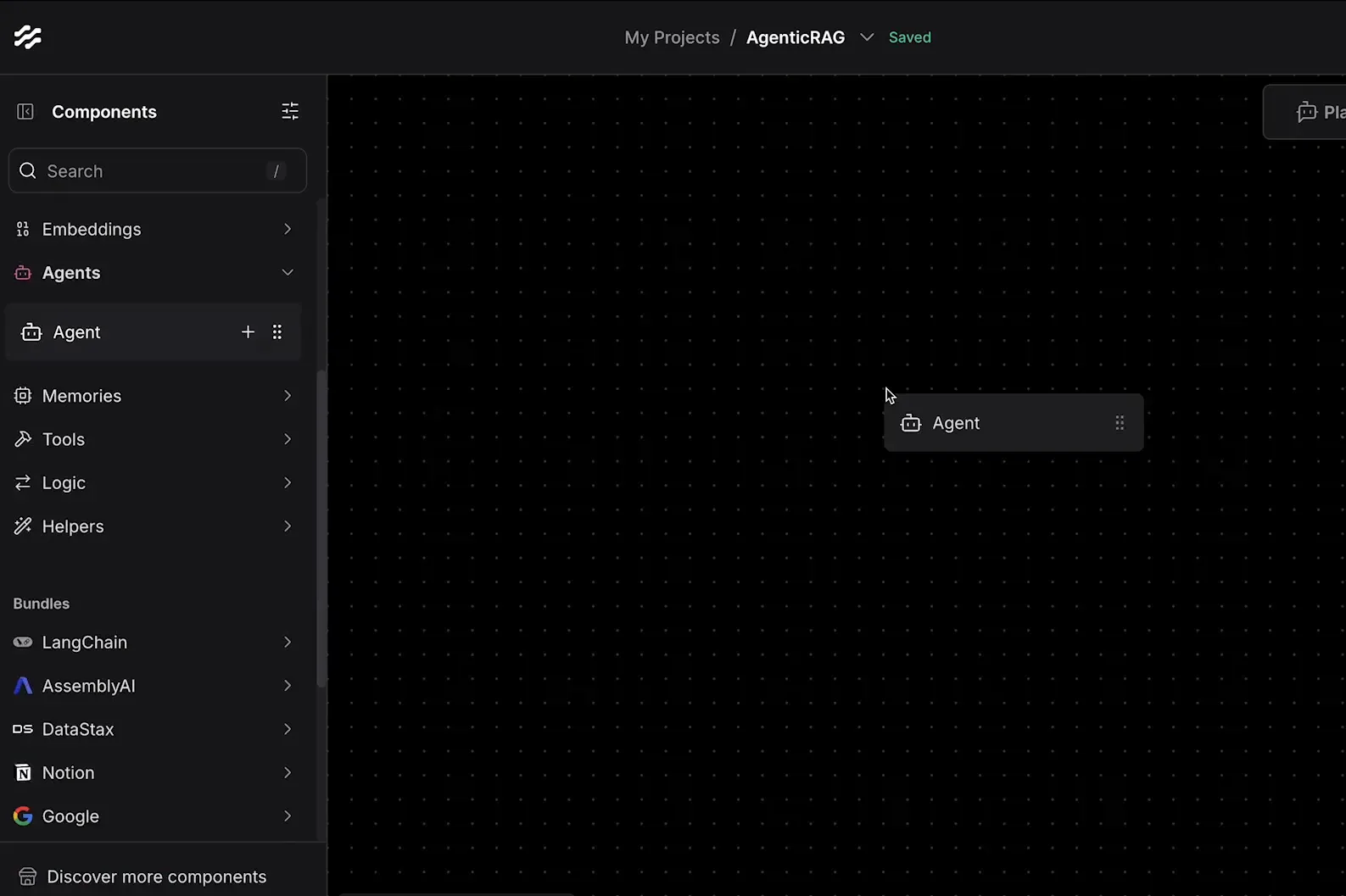
Criando o Agente no Langflow 🤖
Com os dados carregados, o próximo passo é criar um agente que será responsável por interagir com o modelo de linguagem e decidir qual coleção usar para responder às perguntas dos usuários.
A criação do agente envolve os seguintes passos:
Turbine seu Desenvolvimento com Prompts!
Você já sonhou em criar seu próprio aplicativo mas pensou que precisaria ser um gênio da programação? Chegou a hora de transformar esse sonho em realidade! Com as ferramentas no-code de hoje, você pode criar aplicativos profissionais sem escrever uma única linha de código.
- Criar um novo fluxo: No Langflow, inicie criando um novo fluxo e nomeie-o de acordo com a função que ele irá desempenhar.
- Adicionar componentes: Insira os componentes necessários, como o Chat Input para receber perguntas e o Vector Store para acessar as coleções de dados.
- Configurar o agente: Defina a lógica do agente para que ele escolha entre as diferentes coleções com base nas perguntas feitas.
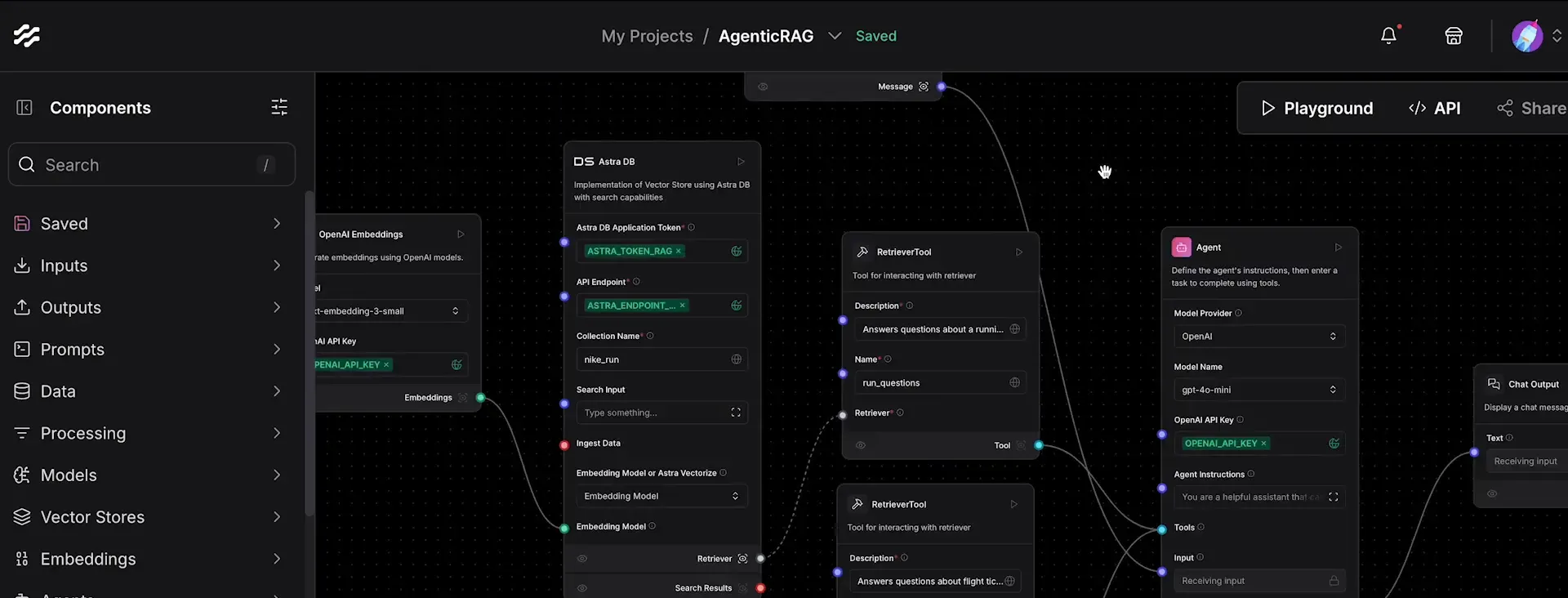
Criando as Tools 🛠️
As ferramentas que o agente utilizará são fundamentais para a recuperação e processamento das informações. Cada ferramenta deve ser configurada para acessar as coleções corretas e gerar respostas relevantes.
O processo de criação das ferramentas envolve:
- Definir ferramentas: Crie uma ferramenta para cada coleção, como “Perguntas sobre Corridas” e “Perguntas sobre Voos”. Cada ferramenta deve ter uma descrição clara que ajude o modelo a decidir quando usá-la.
- Conectar as ferramentas ao agente: As ferramentas devem ser conectadas ao agente para que ele possa utilizá-las conforme a necessidade. Isso permite que o agente faça escolhas informadas sobre qual coleção acessar.
- Testar o fluxo: Após configurar as ferramentas, teste o fluxo para garantir que o agente responde corretamente às perguntas, utilizando a coleção adequada.
Executando o Agente no Playground do Langflow 🛠️
Agora que temos nossos dados carregados, é hora de executar o agente no playground do Langflow. Este ambiente permite testar e visualizar como o agente interage com as coleções que criamos.
Para iniciar, siga os seguintes passos:
- Acessar o Playground: Navegue até a seção do playground no Langflow.
- Selecionar o Fluxo: Escolha o fluxo que você criou para o agente.
- Executar o Agente: Clique no botão de execução para iniciar o agente e aguarde a resposta.
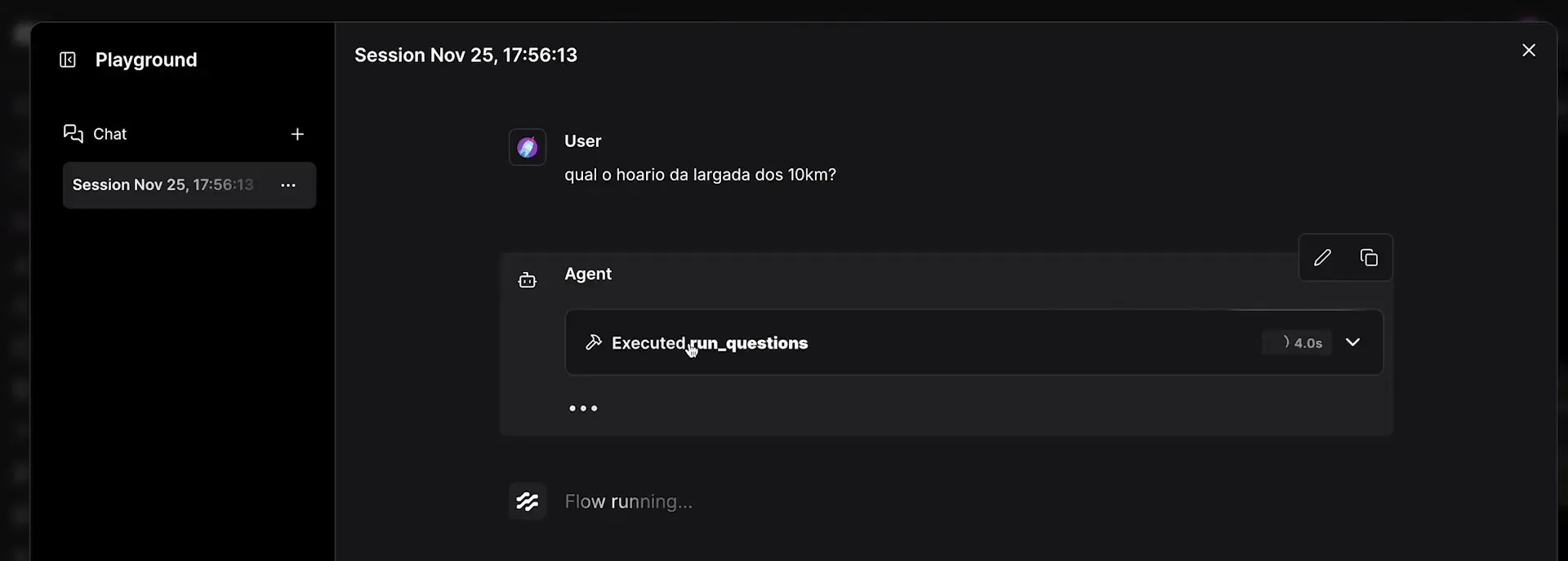
Uma vez que o agente esteja em execução, você poderá fazer perguntas e observar como ele decide qual coleção utilizar. A dinâmica de escolha entre as origens de dados é crucial para a eficácia das respostas.
Tente perguntas específicas sobre cada coleção, como:
- Qual é o horário da corrida?
- Posso remarcar passagens aéreas?
O agente deve ser capaz de alternar entre as coleções e fornecer respostas precisas, mostrando a flexibilidade da inteligência artificial no desenvolvimento frontend design ai.
Monitoramento da Execução 📊
Monitorar a execução do agente é fundamental para entender seu desempenho e ajustar sua lógica. O Langflow oferece ferramentas para rastrear como o agente processa as perguntas e quais dados ele utiliza.
Para monitorar a execução, siga estes passos:
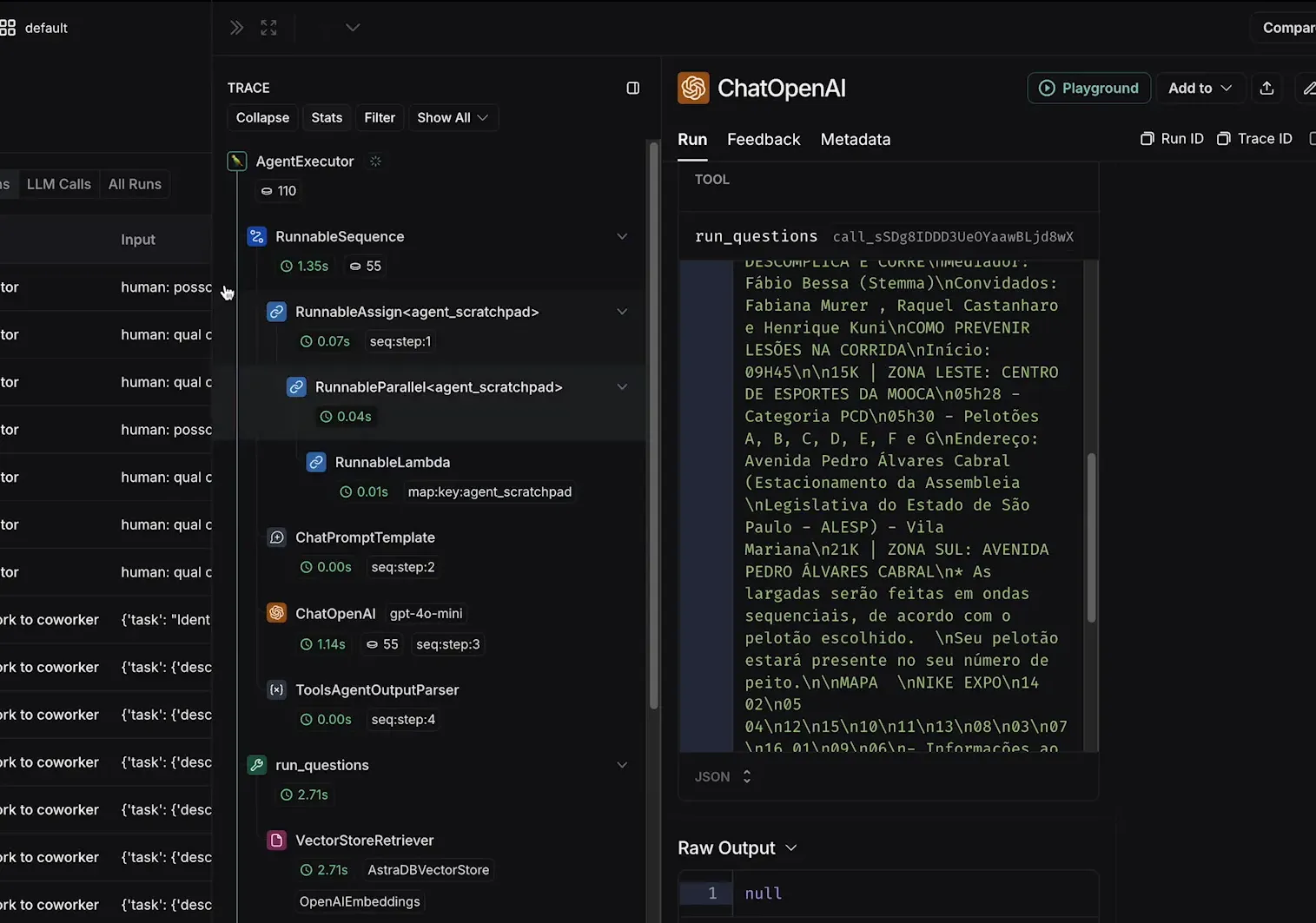
- Visualizar Logs: Acesse a seção de logs no Langflow para ver cada etapa do processamento.
- Analisar Respostas: Verifique as respostas que o agente fornece e quais coleções foram acessadas.
- Ajustar Configurações: Com base nos logs, ajuste a lógica do agente ou as configurações das coleções para melhorar a precisão.
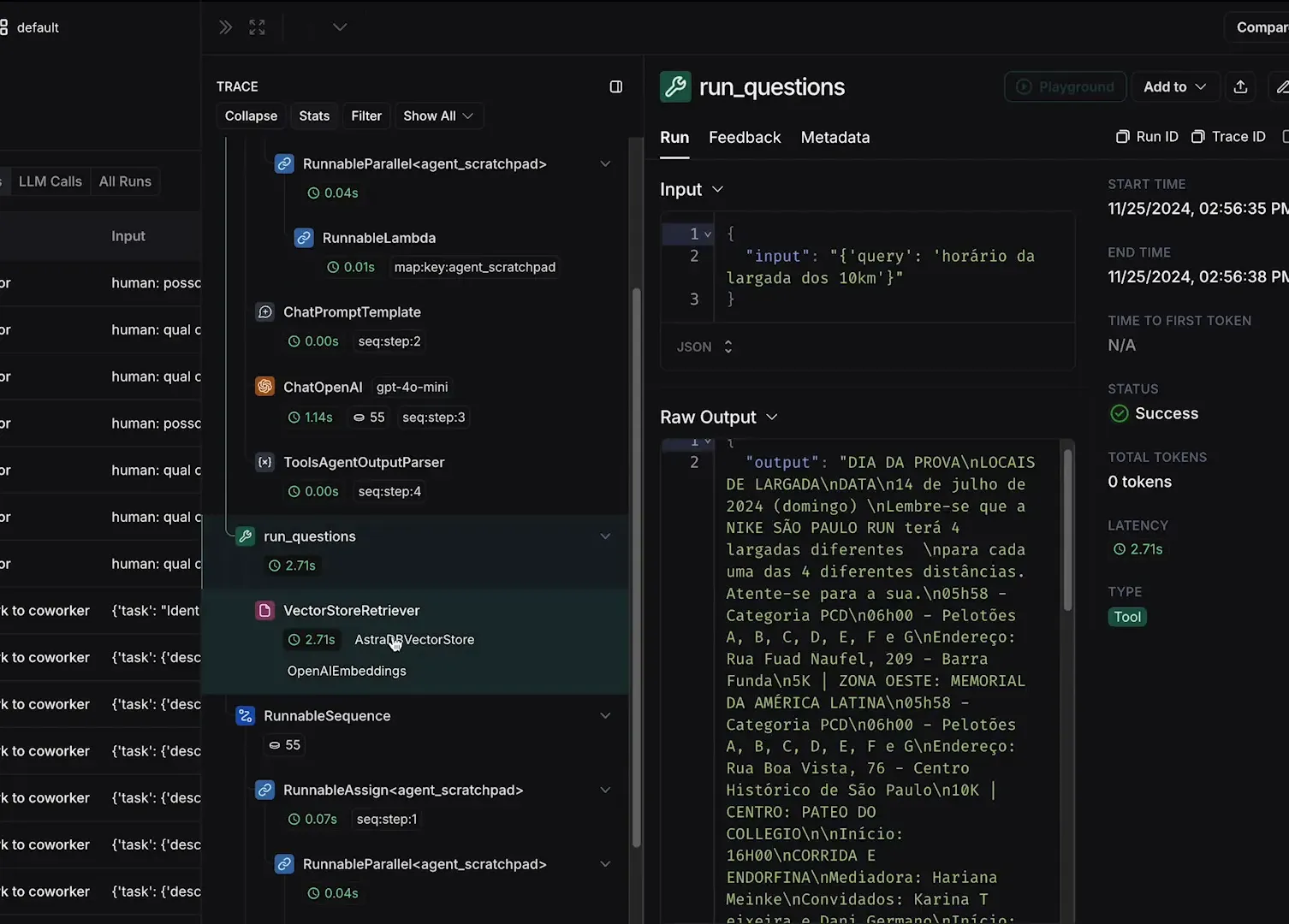
Esses passos são essenciais para garantir que o agente funcione conforme esperado. Você pode até mesmo testar diferentes abordagens e ver como isso impacta as respostas. A capacidade de monitoramento é um dos grandes benefícios da implementação de inteligência artificial no desenvolvimento frontend.
Próximos Passos no Desenvolvimento 🚀
Após a execução e monitoramento do agente, é hora de pensar nos próximos passos. A inteligência artificial no desenvolvimento frontend design ai é uma área em constante evolução, e há várias direções que você pode seguir.
Considere implementar as seguintes melhorias:
- Adicionar mais Coleções: Expanda as fontes de dados do agente para incluir mais tópicos e informações.
- Incorporar Feedback do Usuário: Crie um sistema de feedback onde os usuários possam reportar respostas incorretas e sugerir melhorias.
- Integrar com Outras Ferramentas: Considere integrar o agente com outras APIs e serviços para enriquecer ainda mais as respostas.
Essas melhorias não apenas aumentarão a eficácia do agente, mas também proporcionarão uma experiência mais rica e interativa para os usuários.
FAQ sobre Agentic RAG e AI ❓
Com o crescente uso de agentes de inteligência artificial, surgem muitas dúvidas. Aqui estão algumas das perguntas mais frequentes sobre Agentic RAG e sua implementação:
- O que é Agentic RAG? É uma técnica que combina recuperação de informações de múltiplas fontes com geração de texto, permitindo respostas mais contextuais.
- Como ele se difere do RAG tradicional? O Agentic RAG permite que o agente escolha entre várias origens de dados, enquanto o RAG tradicional se baseia em uma única fonte.
- Quais são os benefícios de usar Agentic RAG? Melhora a precisão das respostas e enriquece a experiência do usuário ao fornecer informações mais relevantes.
- Posso usar o Agentic RAG em aplicações existentes? Sim, a técnica pode ser integrada em aplicações existentes para melhorar a interação com o usuário.
A adoção de inteligência artificial no desenvolvimento frontend não é apenas uma tendência, mas uma necessidade para criar experiências de usuário mais ricas e interativas. Com o Agentic RAG, você está no caminho certo para transformar a forma como suas aplicações interagem com os dados.
Autor
flpchapola@hotmail.com
Posts relacionados

DSPy na prática: programação declarativa com LLMs
O DSPy transforma a forma como lidamos com prompts ao permitir a definição de assinaturas em Python para otimização automática de LLMs....

Quando programar vira prompt: o fim da era do código
A programação evoluiu com a IA, transformando-se de escrita manual de código para um processo de orquestração de prompts. Isso levanta questões...

Quando programar vira prompt: o fim da era do código
A programação evoluiu com a IA, transformando-se de escrita manual de código para um processo de orquestração de prompts. Isso levanta questões...

Como o Cursor transformou meu fluxo de desenvolvimento
O Cursor uniu editor, agentes e automações: planos rastreáveis (.cursor/plans/), Rules & Skills, cloud agents em cursor.com/agents, Debug Mode e comandos (/pr,...

A Revolução Silenciosa: Como a Anthropic e a Bun Estão Transformando o Desenvolvimento de Software com IA
Em 2025, a Anthropic consolidou sua estratégia de dominar a infraestrutura de desenvolvimento de software ao adquirir a Bun, uma startup com...
- Agentes de IA
- AI coding infrastructure
- AI software development
- Anthropic acquires Bun
- Anthropic market strategy
- Automação
- Bun JavaScript runtime
- Bun startup performance
- Claude Code
- Claude Code growth
- Codificação
- desenvolvedores
- Desenvolvimento
- desenvolvimento de software
- Generative AI trends
- Git
- IA
- Inovação
- Integração de IA
- Inteligência Artificial
- Inteligência artificial integrada
- Microsoft Nvidia investment
- OpenAI
- produtividade
- Software automation tools
- Soluções
- Tecnologia
- Tendências de IA

Como Usar Windsurf e Lovable para Criar Landing Pages que Convertem 100% GRÁTIS
Quero mostrar um fluxo prático e reproduzível para criar uma landing page de captura de leads que funcione de verdade, totalmente sem...
Leia tudo